- Dirichlet 过程 参考1 掘金
- 贝叶斯推断
- 贝叶斯网络 Uncertainty in Profit Scoring (Bayesian Deep Learning) 知乎大佬Bayesian Neural Networks:贝叶斯神经网络
- 无偏蒙特卡洛梯度 参考)
- 蒙特卡罗方法(Monte Carlo method)Reinforcement-Learning-Monte-Carlo
- 蒙特卡洛dropoutWhat is Monte Carlo dropout?
- 蒙特卡洛积分 Monte Carlo数学原理 随机模拟-Monte Carlo积分及采样(详述直接采样、接受-拒绝采样、重要性采样)
- Dropout variational inference Dropout变分推理
- reference—深度学习中的两种不确定性
- What My Deep Model Doesn’t Know
- prediction uncertainty 预测不确定性
- 变分贝叶斯方法 cnblog讲解
- 深度学习 回归任务 高斯噪声
- prediction uncertainty 在分类问题中,预测不确定性可以利用蒙特卡洛积分来近似
- 混合尺度高斯先验(scale mixture gaussian prior)
- 自动编码器
自动编码器的基本问题在于,它们将其输入转换成其编码矢量,其所在的潜在空间可能不连续,或者允许简单的插值。 - 变分自动编码器
- 变分推理variational inference 变分推理) 变分推断 贝叶斯神经网络有什么论文可以推荐阅读吗?
- 残差
- 普通残差:
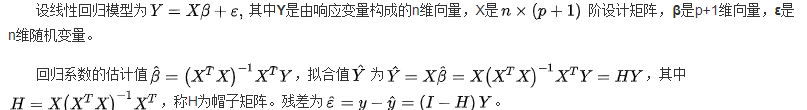
- 残差图:估计观察或预测到的误差error(残差residuals)与随机误差(stochastic error)是否一致
- 普通残差:
- 减弱 错误标签 的影响 PaperReading:Learning with Noisy Label-深度学习廉价落地
- 利用不确定性来衡量多任务学习中的损失函数
- 高斯过程 CS229——Gaussian processes cornell——Lecture 15: Gaussian Processes 高斯过程Gaussian Process教程 krasserm blog——code contained
Gaussian Processes for Machine Learning——book - 深度高斯过程
- 点估计 区间估计
- 贝叶斯推断之最大后验概率(MAP) 花书 19.3节
- Epsilon greedy search
- Confidence calibration 置信度校正 模型的校正度:
- 校正的目的是 makes the confidence scores reflect true probabilities.
- A simple way to visualize calibration is plotting accuracy as a function of confidence (known as a reliability diagram).
- “On Calibration of Modern Neural Networks”
- What is the meaning of the word logits in TensorFlow? logits What does Logits in machine learning mean?
- Batch Normalization 第十节——Batch Normalization)
- 共轭梯度法 共轭梯度法的简单分析)
- 远程监督:主要是对知识库与非结构化文本对齐来自动构建大量训练数据,减少模型对人工标注数据的依赖,增强模型跨领域适应能力。但有 noise problem
基本假设:两个实体如果在知识库中存在某种关系,则包含该两个实体的非结构化句子均能表示出这种关系
知识抽取-实体及关系抽取—DS - Knowledge Graph
- Entity-Centric Knowledge Graph
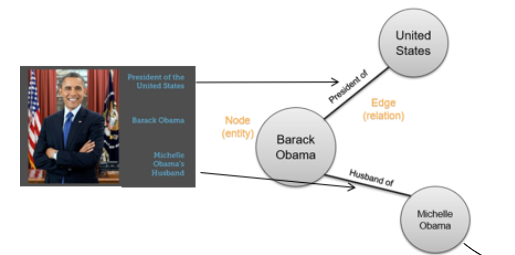

- Event-Centric Knowledge Graph
- Entity-Centric Knowledge Graph
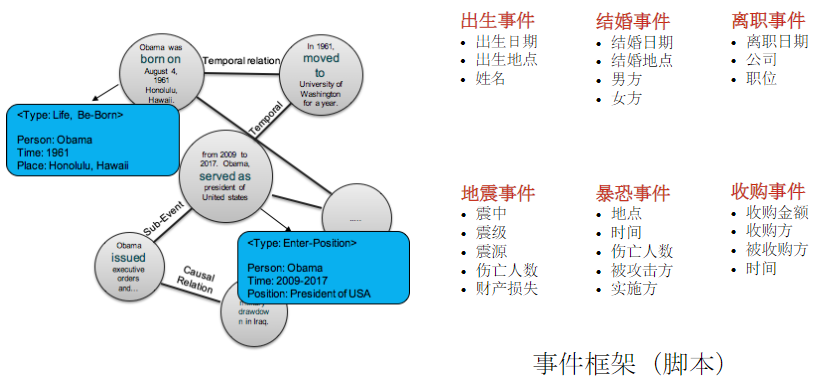
- 事件提取 Event Extraction
定义: Identify the relation between $\color{red}{an event and an entity}$
Event定义:An event is defined as a specific occurrence involving participants
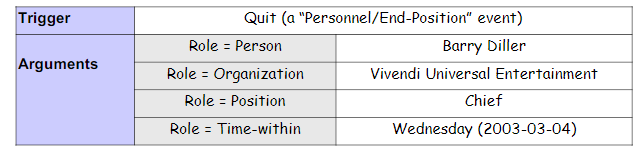
要找到Event trigger, Event Type, Event argument, Argument role
Event 一般与 trigger有紧密关系(Event Identification(TriggerWords)),且 trigger一般为 verb
开放域事件提取 Open Domain Event Extraction
- Features Representation
- Traditional Methods for Feature Representation
- Human designed features
- Too much rely on imprecise NLP tools for feature extraction
- Limitations for low-resources languages
- Dynamic CNN
- Argument Attention(Event arguments)
arguments 识别对Event Detection有很大帮助
If we consider the argument phrase “former protege” (Role=Position), we will have more confidence to predict it as an End-·ition event- 从 contextual words 和 entities 的信息找 arguments—— context representation learning(CRL) 学到 contextual words 和 entities的representation(embedding或是其它),与对应的attention $\alpha$ 内积
- Traditional Methods for Feature Representation
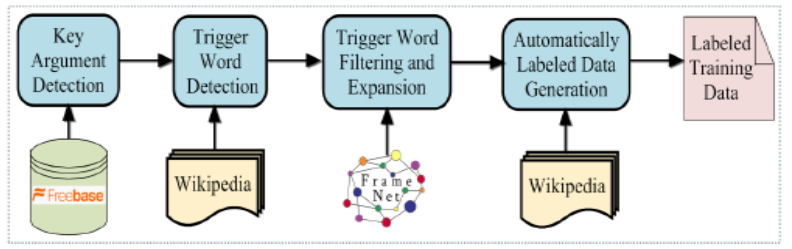
- Training Data Generation
- External Resources
- Employing FrameNet( semantic role descriptions in FrameNet, VerbNet (Kipper etal., 2008) and Propbank (Palmer et al., 2005).) FrameNet & FrameNet Python API

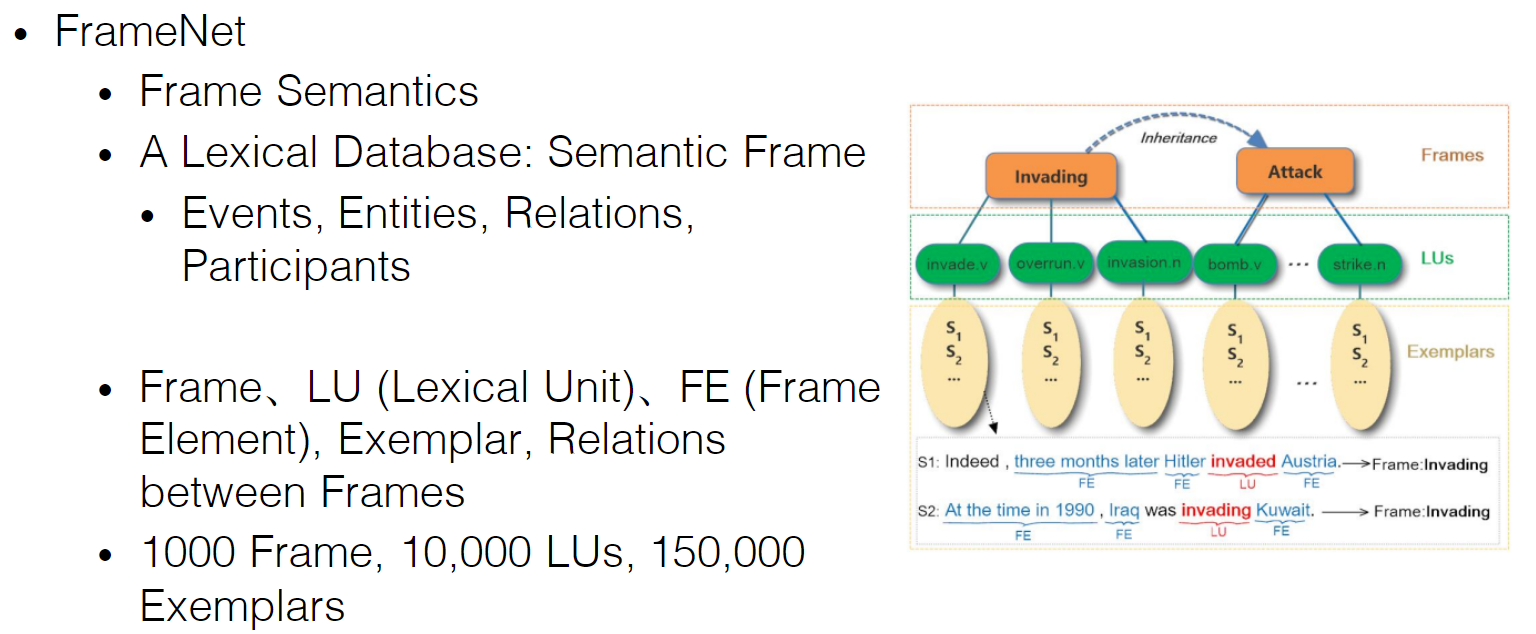
How to generate training data in FrameNet- 方法1 [Open Domain Event Extraction from Texts]
对生成数据准确度的评价
- 方法1 [Open Domain Event Extraction from Texts]
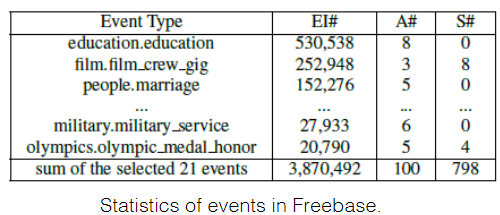
- Employing Freebase 2016年,谷歌宣布将Freebase的数据和API服务都迁移至Wikidata,并正式关闭了Freebase 知识图谱调研-Freebase
- Employing FrameNet( semantic role descriptions in FrameNet, VerbNet (Kipper etal., 2008) and Propbank (Palmer et al., 2005).) FrameNet & FrameNet Python API
- Generating Labeled Data from Structured KB
- Distant Supervision(Weak) Supervision in Relation Extraction($\color{red}{doesn’t}$ work for Event Extraction)
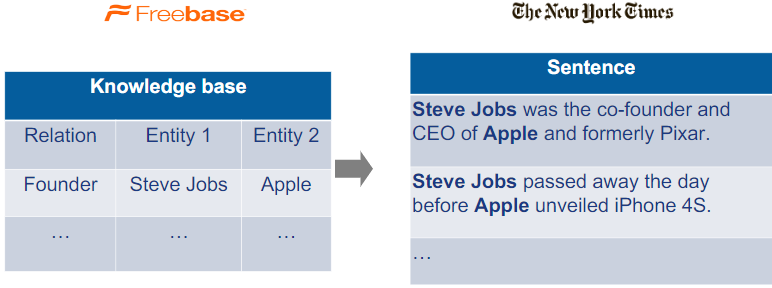
Automatically Labeled Data Generation for Large Scale Event Extraction文中对Freebase 的介绍
- Triggers are not given out in existing knowledge bases 所以没法直接用existing Structured KB
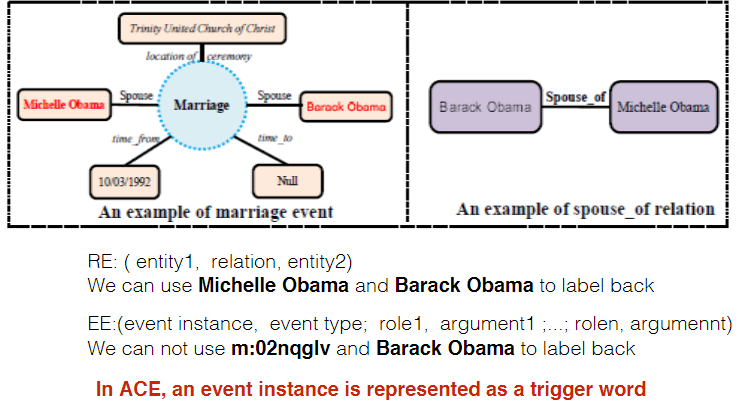
所以可以根据Structured KB中的 Key Arguments label back,依据假设提取Trigger:- Event Trigger Words Extraction
假设:The sentences mention all arguments denote such events - Argument Extraction/Role Identification
根据 Trigger words and Entities
语言学上的规律:Arguments for a specific event instance are usually mentioned in multiple sentences,Only 0.02% of instances can find all argument mentions in one sentence
- Event Trigger Words Extraction
- method
- Distant Supervision(Weak) Supervision in Relation Extraction($\color{red}{doesn’t}$ work for Event Extraction)
- External Resources
- Features Representation
关系抽取 Relation Extraction
定义: Identify the relation between $\color{}{}$ $\color{red}{two given entities}$
实体及关系抽取
事件抽取- Event Extraction(EE) 事件提取
reference1—chriszhangcx blog) and 2—Introduction of Event Extraction
A Survey of Open Domain Event Extraction
事件抽取(Event Extraction)经典模型 - POS tagged pos标记Part of Speech (PoS) Tagging
- ACE Corpus:ACE2005: 529 Training, 33 Development, 40 Testing
- NLTK Natural Language Toolkit3.5
- [Attention Mechanism](https://blog.floydhub.com/attention-mechanism
- 截断梯度法 TRUNCATED GRADIENT
- burn-in (Gibbs sampling) Burn-In is Unnecessary
- LDA 主题模型 一文详解LDA主题模型
- G-test
- 共指和指代消解 Coreference Resolution)
- semantic role labeling representation(SRL) Semantic Role Labeling
meaning representations:Abstract Meaning Representation (AMR)、Stanford Typed Dependencies 、FrameNet Meaning Representation and SRL: assuming there is some meaning
Advanced Semantic Representation
AMR Tutorial
Abstract Meaning Representation (AMR) 1.2Specification - 综述 | 事件抽取及推理 (上)
- word sense 词的意思Word sense
- NLP的任务
- Word2Vec — Skip-Gram) and CBOW
- WordNet sense 到 OntoNotes sense的 mapping tool
- Ontonotes Sense Groups
- 分布语义,Distributional Semantic Representation,基于分布假设:linguistic items with similar distributions have similar meanings.
- GRU 动手深度学习GRU
- DAG有向无环图:
- syntactic parsing语法分析:
- 短语结构树(phrase structure tree 对应语法 context-free grammar CFG 上下文无关法)
- 依存句法树(dependency parse tree): 直观来讲,依存句法分析识别句子中的“主谓宾”、“定状补”这些语法成分,并分析各语法成分之间的关系。
- 语义依存分析 (Semantic Dependency Parsing, SDP):分析句子各个语言单位之间的语义关联,并将语义关联以依存结构呈现
依存句法分析与语义依存分析的区别
Stanford-parser依存句法关系解释 - Distributional Representation和Distributed Representation 聊聊文本的分布式表示—邱锡鹏
- ACE2005:
ACE2005定义的事件抽取是:(1) 以句子级为单位,识别句子中出现的trigger词及类型,(2) 针对每个trigger词,判断其的论元argument以及论元类型。下图即是ACE2005任务的一个示例。 - RNN及变体和BPTT RNN 其常见架构
- dependency parsing 笔记1 笔记2 笔记3
- bootstrapping 自助法
- ELMo ELMo最好用词向量Deep Contextualized Word Representations
- Understanding Ranking Loss, Contrastive Loss, Margin Loss, Triplet Loss, Hinge Loss and all those confusing names
- Multi-instance Learning (MIL) 多实例学习
知乎参考1
南大周志华教授 miVLAD and miFV, - Snorkel - 基于弱监督学习的数据标注工具
snorkel Sonrkel—从0开始构建机器学习项目
reference1
可以视为弱监督源的示例包括:- 领域启发式搜索,例如:常见模式、经验法则等
- 已有的正确标注的数据,虽然不完全适用于当前的任务,但有一定的作用。这在传统上被称为远程监督
- 不可靠的非专家标注人,例如:众包标注
标准函数中编码了领域相关的推理规则,可以使用入正则表达式、经验规则等常见的模式进行标注。这样生成的标注是包含噪声的,并且可能彼此冲突。
常见类型的标注函数: - 硬编码的推导:通常使用正则表达式
- 语义结构:例如,使用spacy得到的依存关系结构
- 远程监督:例如使用外部的知识库
- 有噪声人工标注:例如众包标注
- 外部模型:其他可以给出有用标注信号的模型
当编写好标注函数后,Snorkel将利用这些不同的标注函数之间的冲突训练一个标注模型(Label Model)来估算不同标注函数的标注准确度。通过观察标注函数之间的彼此一致性,标注模型能够学习到每个监督源的准确度。
例如,如果一个标注函数的标注结果总是得到其他标注函数的认可,那么这个标注函数将有一个高准确率,而如果一个标注函数总是与其他标注函数的结果不一致,那么这个标注函数将得到一个较低的准确率。通过整合所有的标注函数的投票结果(以其估算准确度作为权重),我们就可以为每个数据样本分配一个包含噪声的标注(0~1之间),而不是一个硬标注(要么0,要么1)。
接下来,当标注一个新的数据点时,每一个标注函数都会对分类进行投票:正、负或弃权。基于这些投票以及标注函数的估算精度,标注模型能够程序化到为上百万的数据点给出概率性标注。最终的目标是训练出一个可以超越标注函数的泛化能力的分类器.通过这种方法得到海量的低质量监督,然后使用统计技术处理有噪标注,我们可以训练出高质量的模型。
参考—Sonrkel—从0开始构建机器学习项目(完善中)
sample_and_sgd函数: (计算在某一分布下的期望时,用蒙特卡洛积分近似, 去掉极限可以看成是采样点的均值)
为了获得指定分布的样本点,我们需要进行采样。对于高维的联合分布,我们通常使用Gibbs采样算法
- Gibbs采样算法 Gibbs采样的原理
- PGM 概率图模型
An Introduction to Factor Graphs
Snorkel、PGM and sampling、SGD相关论文 - Factor Graphs and the Sum-Product Algorithm
- 结构学习 structure learning
贝叶斯网路的学习包括:参数学习、结构学习
李宏毅 4 episode Structured Learning 1: Introduction - 半监督 ML Lecture 12: Semi-supervised
- 利用生成模型从噪声标签源合成标签:
- 玻尔兹曼机 RBM
受限玻尔兹曼机(RBM)原理总结 - 命名实体 NER 命名实体识别 NER 论文综述
- Highway Networks Highway Networks及HBilstm Network
- entity span detection:找出 文本中指向同一实体的所有文段,这是因为,人们对同一个实体往往有多种不同的说法,如代词、省略词、别名等等。 reference—基于span prediction的共指消解模型

- 如何理解LSTM后接CRF?
CRF和LSTM 模型在序列标注上的优劣? - Viterbi(维特比算法)HMM+Viterbi(维特比算法)+最短路径分析
- 知识图谱上的实体消歧 一些关于NER任务调研的小思考
- 实体词典:entity dictionary
- What are Chunks ?
Chunks are made up of words and the kinds of words are defined using the part-of-speech tags. One can even define a pattern or words that can’t be a part of chuck and such words are known as chinks.
What are IOB tags ?
It is a format for chunks. These tags are similar to part-of-speech tags but provide can denote the inside, utside, and the beginning of a chunk. Not just noun phrase but multiple different chunk phrase types are allowed here.
code
自然语言处理之从文本中提取信息
7. Extracting Information from Text—nltk - Karush-Kuhn-Tucker (KKT)条件
- An Introduction to Statistical Learning with Applications in R
- collective classification jointly determine the correct label assignments of all the objects in the network.
- ontology alignment 本体对齐
- personalized medicine 个性化医学
- opinion diffusion 意见传播
- trust in social networksolollllllllllllllllllll+
- graph summarization
- t-norm: t-norm is a binary algebraic operation on the interval [0, 1], 三角范数,用于模糊逻辑
- MPE inference 贝叶斯网络与最大可能解释(MPE)问题 MostProbable Explanation, MPE
- 共识优化 consensus optimization
- knowledge distillation知识蒸馏: 知乎1, 知乎2, paper reading list
- 后验正则化(posterior regularization)方法
- K-dimensional probability simplex
- max-over-time 池化层,NLP中的CNN: 参考1cnblog Pooling vs Pooling-over-time
- Bidirectional LSTM-CNN (BLSTM-CNN) Training System_Training_System)
- projected gradient descent (PGD)投影梯度下降
投影梯度下降法解正则化问题:以Lasso回归为例
Professor Bingsheng He—基于梯度投影的凸优化收缩算法和下降算法 - 利普西茨条件
Lipschitz condition - Berkeley Math
非凸优化基石:Lipschitz Condition - 知乎
Existence and Uniqueness 1 Lipschitz Conditions - CAM 和 Grad-CAM
热力图?Class Activation Mapping - self-training
- ULMFiT——文本分类通用训练技巧
- Transformer
Attention head Self-Attention与Transformer
multi-head attention - warmup 神经网络中 warmup 策略为什么有效
- Zero Shot 零次学习(Zero-Shot Learning)入门
- NLP Subword算法:BPE、WordPiece、ULM
- Pytorch 训练加速
- Categorical Cross-Entropy LossUnderstanding Categorical Cross-Entropy Loss, Binary Cross-Entropy Loss, Softmax Loss, Logistic Loss, Focal Loss and all those confusing names
- 学生t-分布
- 概率单纯形 Simplex
- adamw优化器 AdamW and Super-convergence is now the fastest way to train neural nets 中文
Keras优化器的用法 - metric learning Metric Learning科普文
Deep Metric Learning
What is Metric Learning?—scikit-learn
深度度量学习综述
General Pipeline:
一般来说,DML包含三个部分:特征提取网络来map embedding,一个采样策略来将一个mini-batch里的样本组合成很多个sub-set,最后loss function在每个sub-set上计算loss.- Isotonic Regression 保序回归 使用 Isotonic Regression 校准分类器
- Margin Based Loss
- Triplet Loss
- Contrastive loss
- Maximum Inner Product Search 最大点积向量检索
- Locality Sensitive Hashing :Unlike space partitioningtechniques, both the running time as well as the accuracy guarantee of LSH based NNS are in a wayindependent of the dimensionality of the data
- tornado Python web框架和异步网络库 Tornado Web Server — Tornado 4.3 文档
- 如何理解皮尔逊相关系数(Pearson Correlation Coefficient)?
- BatchNormalization、LayerNormalization、InstanceNorm、GroupNorm、SwitchableNorm总结
- 彩票假设
- Deep SSL系列4: Mean Teacher
半监督深度学习又小结之Consistency Regularization - 半监督VAT(虚拟对抗训练)论文解读
- 维基数据 (Wikidata) 是一个怎样的项目?
Welcome to Wikidata——官网
Wikidata:SPARQL query service/queries/examples
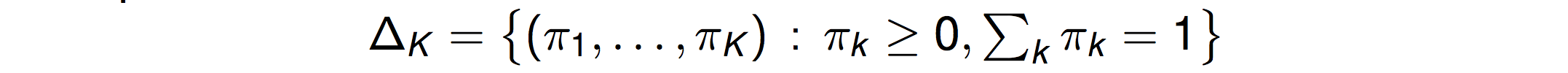
相关论文
- Joint event extraction via recurrent neural networks 论文解读
- 【论文笔记】Graph Convolutional Networks with Argument-Aware Pooling for Event Detection 笔记2
- Jointly Extracting Event Triggers and Arguments by Dependency-Bridge RNN and Tensor-Based Argument Interaction 笔记1 笔记2