『Liberal Event Extraction and Event Schema Induction』阅读笔记
- 抛开ACE2005等固有的event schema
- 以 distribution hypothesis 为依据,提出两个假设
- 以这两个假设为依据,将 event trigger 的上下文中包含的 argument和argument对应的role和type 作为给 trigger 进行聚类的依据(通过聚类给trigger生成type,聚的新类就产生新的trigger type,超越ACE这些固有schema)
- 对 argument的选取依据是 AMR meaning representation,trigger和其他word间的 semantic relation
- word 的 embedding 都是用 一个 大型的语料库通过常见的 wod2vec得到的general embedding
code
文中训练过程和推理过程混在一起说,比较混乱
专有名词
Abstract
discover event schemas from any input corpus simultaneously
我们提出了一个全新的“自由的”EventExtraction范例,它可以同时从任何输入语料库中提取事件和发现事件模式。我们结合语义(如抽象意义表达)和分布语义来检测和表示事件结构,并采用联合类型框架来模拟抽取事件类型和论证角色,发现事件模式。对一般领域和特定领域的实践表明,该框架可以构建具有多种事件和参数角色类型的高质量模式,在手动定义的模式中涵盖了很大比例的事件类型和争论角色。我们展示了所发现模式的提取性能与从根据预定义事件类型标记的大量数据中训练出的监督模型相当。
1 Introduction
手动定义的事件模式缺点:Manually-defined event schemas often provide low coverage and fail to generalize to new domains.
文章提出的pipelined system可以automatically discovers a complete event schema, customized for a specific input corpus.
文中举例:

对提取出的event triggers and event arguments进行聚类,each cluster represents a type,聚类的依据是distributional similarity(类似于Brown Cluster ?)。关于distributional similarity的依据是一个假设:The distributional hypothesis (Harris, 1954) states that words often occurring in similar contexts tend to have similar meanings. 于是作者对trigger的type的判断做出了下面两个假设:
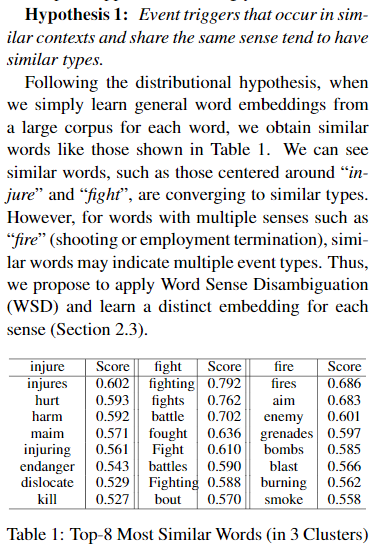

- when we simply learn general word embeddings from a large corpus for each word,可观察到类似的词,比如那些围绕“injure”和“fight”的词,倾向于相似的类型,然而,对于具有多种含义的词,如“fire”(射击或解雇),similar的词可能表示多种事件类型。因此,我们建议应用词义消歧(WSD)并学习每个意义word sense的独特嵌入(2.3节)
- 上下文不同对trigger 的type确定也有影响。We therefore propose to enrich each trigger’s representation by incorporating the distributional representations of various words in the trigger’s context. ——如何挑选要放在上下文中的词? 依靠semantic relations
2 Approach
pipelined system
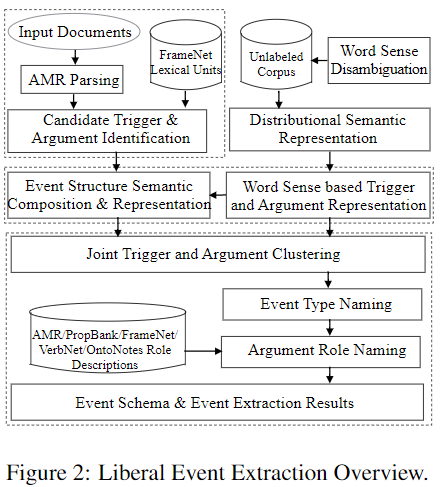
对于输入文本的event extraction和event schema过程
Given a set of input documents, we first extract semantic relations( AMR relations 上图左边虚线框), apply WSD词义消歧(WSD用的算法是?) and learn word sense embeddings(上图右边,消歧后输出一个较确定的sense,然后对这个sense学习embedding吗?). Next, we identify candidate triggers and arguments.
为了trigger type的准确性,需要生成trigger’s event structure representation,同时生成Argument representations
Trigger and argument representations被同时送入 joint constraint clustering framework进行聚类,对聚类结果命名得到 event type name,通过the meaning representation and semantic role descriptions in FrameNet, VerbNet (Kipper etal., 2008) and Propbank (外部KG)间的对应关系 做 argument role labeling
还做出了一点贡献:比较不同的meaning representations semantic relations connecting triggers to context words are derived from three meaning representations 使用 CAMR,Stanford’s dependency parse, SEMAFOR 分别从Abstract Meaning Representation (AMR), Stanford Typed Dependencies,FrameNet 三种meaning representations提取semantic relations
3 系统拆分分析
candidate event triggers: Given a sentence, we consider all noun and verb concepts that are assigned an OntoNotes sense by WSD as candidate event triggers.(Word Sense Disambiguation Using OntoNotes: An Empirical Study). Any remaining concepts that match both a verbal and a nominal lexical unit in the FrameNet corpus are considered candidate event triggers as well. 一段句子内所有的在Ontonotes Sense Groups 中的verb和noun都作为candidate
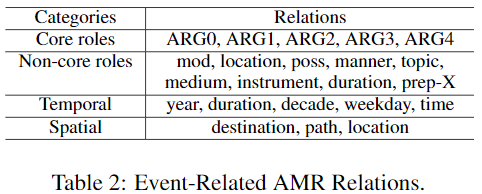
Argument Identification: all concepts 和 candidate event trigger间有 semantic relations的都作为 candidate arguments—— semantic relations是在一个 manually-selected set中的—— For dependencies, we manually mapped dependency relations to AMR relations and use Event-Related AMR Relations (dependency relations 怎么更好利用?)
(用 AMR relation 和 candidate event trigger 找到 candidate arguments)
为sense 学习embeddings,( map WordNet sense output to OntoNotes senses这一步的意义是什么?)
used the August 11, 2014 English Wikipedia dump to learn trigger sense and argument embeddings.
对 unlabled corpus 应用 WSD,根据描述最终得到
 对candidate trigger的sense的推理,然后再是训练trigger sense 的embedding
对candidate trigger的sense的推理,然后再是训练trigger sense 的embedding
为了 incorporate inter-dependencies between event and argument role types (event 相应的 argument role之间有必然的依赖) into our event structure representation。许多 meaning representations could provide,采用 semantic relations from meaning representations using AMR.
提取与 event trigger(with sense,即trigger包含确定的词义) 语义相关的 words
提出 Tensor based Recursive Auto-Encoder (TRAE) ——对根据 AMR 得到的 Event Structure编码成一个 representation
目的是 we aim to exploit linguistic knowledge to incorporate inter-dependencies between event and argument role types在表示中融入依赖关系
对 AMR semantic relations的每个子集应用一个 composition function ,然后compose the event structure representation 基于这些 function。
AMR semantic relations的自己是作者手动选择的认为分类trigger type有帮助:
对于两个 word vector和 AMR relation $:mod$ 定义输出 相同维度的representation vector的公式:
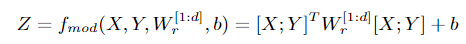
use the statistical mean(average) to compose the words connected by “:op” relations
当完成将两个word 根据 relation 进行compose后,将输出的vector apply an element-wise sigmoid activation function 得到 hidden layerrepresentations $Z$ ,autoencoder的思想,利用重建结果的reconstruction errors去 optimize $Z$ :

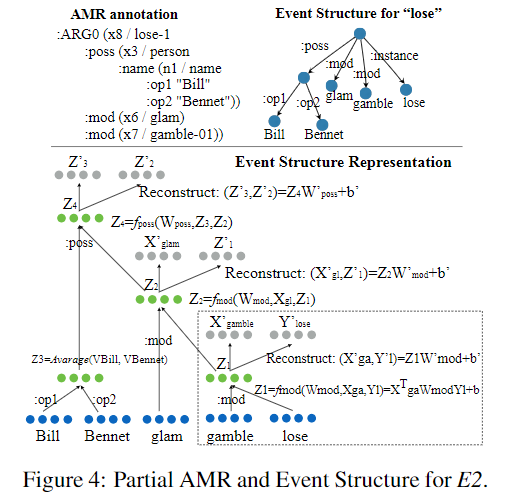
(感觉不能叫event structure,应该叫sentence structure)
中间的每个向量表示$Z_1 Z_2$ 都表示 trigger 和 argument 以及 relation r 的语义关系的表示
SGD来优化这个目标
Recursive:当得到composition vector of $Z_1$ 后,将 $Z_1$ 和下一个word vector compose
为每种 event structure 生成一个 representation
trigger 和 arguments 的 type 确定
We observe that, for two triggers t1 and t2, if their arguments have the same type and role, then they are more likely to belong to the same type
让相似的trigger 有相同的type
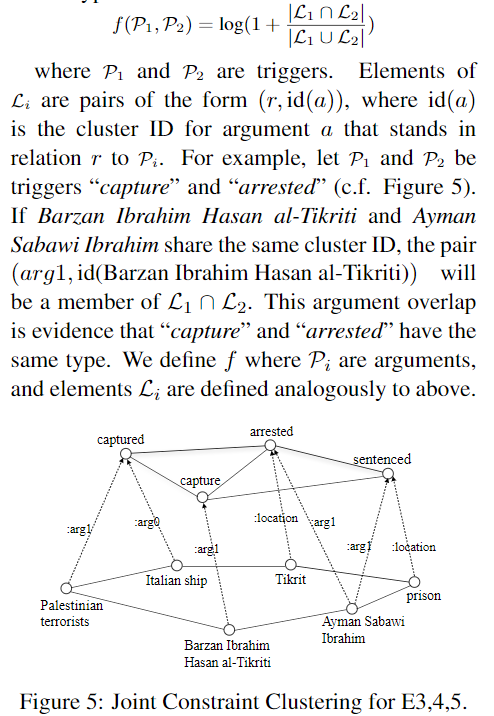
trigger间的相似度
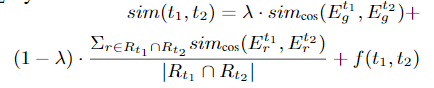
argument 的 type 和 role 是与 trigger 间的 relation 相关,trigger sense的embedding表示不能直接说明相似,还与argument有关,但这里感觉没有体现argument same type and role,$E_r^{t}$ 是直接trigger和argument串联经过变换得到的,在relation已经相同的情况下,argument 用的只是general lexical embeddings,那不同的argument显然会导致 sim 的值下降
对于argument间的相似度
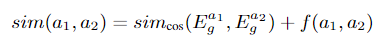
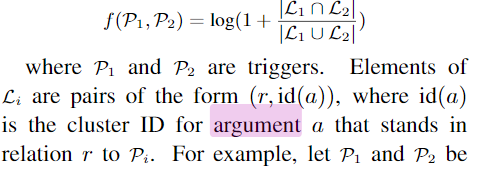
f 函数对 trigger 作为 自变量 是有定义的,对于 argument呢?文章没有明确指出。
joint constraint clustering approach, which iteratively produces new clustering results based on the above constraints.

同时给argument 和 trigger 进行clusting:
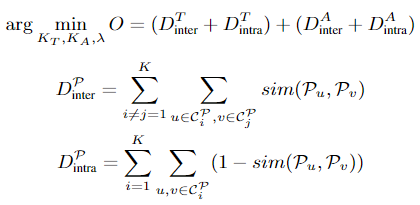
目标函数的优化方法使用 谱聚类
we utilize the trigger which is nearest to the centroid of the cluster as the event type name
For a given event trigger,first map the event trigger’s OntoNotes sense to PropBank, VerbNet, and FrameNet
AMR: 对 AMR 的argument map到 FrameNet VerbNet PropBank
Stanford Typed Dependencies:
4 Evaluation
Schema Discovery



