『Data Programming:Creating Large Training Sets, Quickly』阅读笔记
Basics Tutorial for Snorkel MeTaL
Snorkel Drybell:在行业规模部署弱监督的案例研究
Snorkel应用实例:Building NLP Classifiers Cheaply With Transfer Learning and Weak Supervision
整个流程大体可以分为3部分:
弱监督或无监督数据源采集,包括采集无标签数据、构建领域词表等;
编写LF函数,生成对样本集的标注向量; 训练生成式模型对样本长生概率标注;
利用第二步生成的带标注的数据训练复杂的判别型模型,比标注函数LF有更好的泛化能力(比如CNN、RNN等)
把整个模型看成是集成学习(ensemble learning),每个LF都可以看成是一个弱分类器
生成模型基于概率图模型,用factor来建模变量间的依赖关系。单变量因子用来建模图中变量的先验分布;多变量因子建模多个变量之间的关系,联合分布。
样本的真实标签 Y 看作是模型的隐变量。要建模所有LF对样本生成的标注向量和真实标签的联合概率,要通过优化得到的模型参数是每个LF给出pseudo labels的权重,在并不知道真实标签分布即先验分布时,用最大对数似c然估计参数,因此计算中用到将真实标注marginalized的marginal 概率(论文中优化的模型参数是一个LF对一个样本进行标注的概率和标注正确的概率,对这两个随机变量设置了取值范围,感觉和集成学习中应用Hoeffding来算上下界有关)
对上面的优化目标求梯度,根据蒙特卡洛积分,最终只需要把每次采样到的两个分布的样本点带入到对应的因子函数中求出对应的值,再计算两者只差即可。为了获得指定分布的样本点,对于高维的联合分布通常使用Gibbs采样算法
摘要
我们表明,通过将训练集标记过程明确表示为一个生成模型,我们可以对生成的训练集进行“去噪”,并在理论上确定我们可以在少数几个设置中恢复这些生成模型的参数。然后,我们展示如何修改判别损失函数 discriminative loss function以使其是噪声敏感noise-aware的。并且在包括Logistic回归和LSTM在内的一系列判别模型中证明了该方法。此外,当训练数据有限或不可用时,数据编程可能是非专家更容易创建机器学习模型的方式。
专有名词
data programming
weak supervision strategies
domain heuristics ——labeling functions:程序标记了数据的子集,但是标记的label are noisy and may conflict。
labeling functions——用户无需手动标记每个示例,而是通过提供一组启发式规则来描述可以标记这些示例的过程
TAC-KBP Slot Filling challenge,
asymptotic scaling ——渐近缩放,流行学习?
relation extraction tasks——关系提取任务
urrounding textual patterns——周围文本模式
discriminative feature-based mode
hierarchical topic models——分层主题模型
Co-training——views of the data
factor graph

Gibbs sampling
snorkel Sonrkel—从0开始构建机器学习项目
近似集成学习 ensemble learning 集成学习)
1 简介
过去十年中许多重要的机器学习突破都受到新标签训练数据集的发布的推动。使用此类数据集的监督学习方法Supervised learning approaches 已越来越成为整个科学和工业应用的关键构建块。自动化特征生成方法automated feature generation approaches的最新成功经验也推动了这一趋势,特别是深度学习方法,例如长期短期记忆(LSTM)网络,在具有足够大标签的训练集的情况下,该方法减轻了特征工程的负担。但是,对于许多实际应用程序,不存在大型的手工标记训练集,并且由于要求标记者必须是应用程序领域的专家,因此训练集的创建成本过高。此外,应用程序的需求经常变化,因此需要新的或修改的训练集。
为了帮助减少训练集创建的成本,我们提出了data programming,它是训练数据集的编程创建和建模的范例。数据编程为weak supervision提供了一个简单,统一的框架,在该框架中,训练标签有噪声,并且可能来自多个可能重叠的来源。在数据编程中,用户以labeling functions的形式对这种弱监督进行编码,标签函数是用户定义的程序,每个程序都为数据的某些子集提供标签,并共同生成大量但可能重叠的训练标签集。
许多不同的弱监督方法可以表示为标记功能,例如利用现有知识库的策略existing knowledge bases (就像在DS中一样)为许多个人注释者的标签建模(如在众包中)或利用特定于领域的模式和词典patterns and dictionaries的组合——所以,labeling functions 的错误率可能变化很大,并且在某些数据点上可能会发生冲突。————所以我们将labeling functions建模成generative process,通过学习标记函数的准确性及其相关结构,自动对所得的训练集进行降噪处理。反过来,我们使用该训练集模型来优化我们希望训练的判别模型的损失函数的随机形式。我们表明,在labeling functions,具有特定条件的情况下,我们的方法实现了与监督学习方法相同的渐近缩放,但是我们的缩放取决于未标记数据unlabeleddata的数量,并且仅使用固定数量的标记函数 labeling functions
Data programming,例如,考虑以下场景:当两个质量和范围不同的 labeling functions重叠并且在某些训练示例上可能发生冲突时;在先前的方法中,用户将不得不决定使用哪个信号,或者如何以某种方式将两者的信号集成在一起。在数据编程中,我们通过学习包含两个 labeling functions的训练集模型来自动完成此任务。另外,用户经常知道或能够推断出其 labeling functions之间的dependencies依赖性。在数据编程中,用户可以提供一个依赖图dependency graph,以表明例如两个标记功能相似,或者一个“固定”fixes”或“加强”“reinforces”另一个。我们描述了一些案例,在这些案例中我们可以学习这些依赖性的强度the strength of these dependencies,,并且对于它们的泛化generalization也渐近地与监管方法相同。 (集成学习)
我们的方法的另一个动机是由于观察到用户经常为模型的选择特征selecting features而苦恼,这是给定固定大小的训练集的传统开发瓶颈。但是,来自用户的初步反馈表明,在数据编程框架中编写标签功能writing labeling functions可能更容易。虽然一个特征的最终性能的影响取决于训练集和模型的统计特性,但a labeling function具有简单直观的最佳性标准:可以正确标记数据。以此为动力,我们探索了是否可以颠覆传统的机器学习开发流程,让用户专注于生成足够大的训练集以支持自动生成的特征。
Summary of Contributions and Outline
我们的第一个贡献是数据编程框架,在该框架中,用户可以比以前的方法更灵活,更通用的方式隐式描述训练集的丰富生成模型。在第3节中,我们首先探讨一个简单的模型,其中标记函数是有条件独立的。我们在这里表明,在某些条件下,样本复杂度几乎与标记的情况相同。在第4节中,我们将结果扩展到更复杂的数据编程模型,在众包中泛化得到相关的结果[17]。在第5节中,我们通过实验验证了我们在基因组学,药物基因组学和新闻领域中的大型现实文本关系提取任务上所采用的方法,该方法在基线DS方法上显示出平均2.34分的F1得分提高-包括获得新的竞争得分在2014年TAC-KBP插槽填充竞赛中。使用LSTM生成的功能,我们将在竞争中排名第二,比最新的LSTM基线获得5.98分的F1分数增长[32]。此外,我们描述了一组生物信息学用户从可用性研究中获得的有希望的反馈
2 Related Work
- Distant supervision 是通过编程方式创建训练集的一种方法,典型的例子是从文本中提取关系relation extraction,其中将已知关系的知识库启发式heuristically 映射到输入语料库 [8,22]。基本extension是通过围绕文本模式将示例分组,将问题变成multiple instance learning [15, 25].;其他extension使用基于判别性基于特征的模型discriminative feature-based mode [26]或生成式模型对这些周围文本模式的准确性进行建模[1, 27, 31].。像我们的方法一样,这些后来的方法为训练集创建的生成过程generative process建模,但它们不是基于用户的输入as in our approach。还有很多示例,其中以与我们的方法类似的方式,从未标记的数据[7]或直接从用户[21、29]收集用于标记训练数据的其他启发式模式heuristic patterns ,但没有任何框架可以处理以下事实: labels are explicitly noisy
- Crowdsourcing 被广泛用于各种机器学习任务 [13, 18]. 与我们的问题设置特别相关的是一个理论问题,即如何在没有可用的ground truth的情况下对各种专门领域数据的准确性进行建模,这是在Crowdsourcing背景下提出的[10]。 [4,9, 16, 17, 24, 33]中provide formal guarantees even in the absence of labeled data。我们的模型可以捕获the basic model of the crowdsourcing setting,并且在独立情况下可以视为等效模型(第3节)。除了超越仅从人类注释者中得到输入之外,我们还对用户提供的“labelers“之间的依赖关系进行建模,这在Crowdsourcing的语境中是不自然的。此外,尽管众包结果侧重于大量标记者,每个标记者都对数据的一小部分进行标记,但我们考虑了一小部分标记函数,每个标记函数都对数据集的大部分进行了标记
- Co-training协同训练是通过选择两个条件独立的数据视图views of the data来有效利用少量标记数据和大量未标记数据的经典过程[5]。除了不需要一组标记数据,并允许两个以上的视图(在我们的情况下为标记函数)之外,我们的方法还允许对视图之间的依赖关系进行显式建模,例如,允许对观察到的与视图 views之间的依赖关系进行显式建模[19]
- Boosting 用于组合许多“弱”分类器的输出以在supervised setting中创建强分类器[28]。最近,已经提出boosting-like 的方法,该方法除了利用标记数据之外还利用了未标记数据,该方法还用于对所集成 ensembled的各个分类器的准确性设置约束[3]。这在本质上与我们的方法类似,除了在我们的方法中标记数据不是明确必需的,并且支持“启发式”分类器(标记函数)之间更丰富的依赖关系richer dependency structures结构。
- 在经典[20]和最近的情况下[23]都讨论了带有噪声标签的学习的一般情况。还已经在标签噪声鲁棒logistic回归in the context of label-noise robust logistic regression的背景下进行了专门研究[6]。我们考虑更普遍的情况,其中多个嘈杂的标签功能可能会发生冲突并具有依赖性。
3 The Data Programming Paradigm
动机:在许多应用程序中,我们想使用机器学习,但是我们面临以下挑战:(i)手工标注的训练数据不可用,并且要获得足够数量的数据过于昂贵,因为它需要昂贵的领域专家标记;(ii)相关的外部知识库不可用或不够具体,从而排除了传统的远程监管或共同培训方法;(iii)应用规范不断变化,从而改变了我们最终希望学习的模型。——是训练集以编程方式创建的范例,它使领域专家可以更快地训练机器学习系统,具有这种类型的预期损失缩放的潜力has the potential for this type of scaling of expected loss。

这一段指什么?
在本文的其余部分中,我们将重点放在 binary classification 任务中,其中我们具有分布$\pi$ over object,有 class pairs$(x,y)\in \chi \times\{-1,1\}$,我们关心在给定一些特征的线性模型linear model下使logistic损失最小
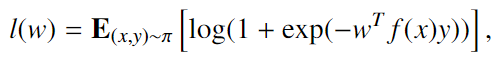
不失一般性地,我们假设$||f(x)||\leq1$.
labeling function$\lambda_i:\chi\mapsto\{-1,0,1\}$ 用户定义的函数,对某些 domain heuristic编码,为对象的某些子集提供(非零)标签。用户提供m个labeling function,我们将其向量化为$\lambda:\chi\mapsto\{-1,0,1\}^m$
举例一个简单的文本关系提取text relation extraction来得到直观印象:给定句子“Gene A causes disease B”,则对象x=(A,B) 有真实分类y=1. w为了构建训练集,写了三个labeling functions:
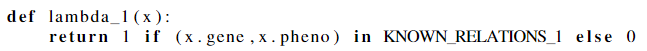
$\lambda_1$ : 外部结构化知识库用于标记一些对象的准确性相对较高,相当于传统的远程监管用于关系抽取
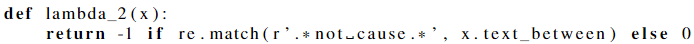
$\lambda_2$ : 使用纯粹的启发式方法以较低的准确度标记大量示例
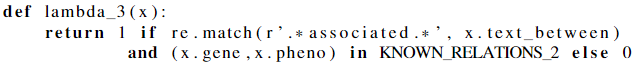
$\lambda_3$ : 是一种“混合”标签功能,它利用了知识库和启发式方法
labeling function 不必具有完美的准确性或召回率;相反,它表示用户希望赋予impart to其模型的模式pattern ,并且比起一组手工标记的示例用labeling function更容易。labeling functions 可以基于外部知识库,库或本体 ontologies,可以表达启发式模式或这些类型的某种混合形式;我们在实验中看到存在这种多样性(个体学习器间要有一定的多样性)的证据————labeling functions 可能会重叠,冲突甚至具有依赖性,用户可以将其作为数据编程规范的一部分提供——为输入这些labeling functions提供了框架
Independent Labeling Functions
我们首先描述一个模型——一个生成模型,labeling functions 单独打标签,其中给定 true label class——labeling functions $\lambda_i$有$\beta_i$ 的可能性为一个object 打标签(覆盖率),有$\alpha_i$ 的可能性正确标记对象(准确性),为简单起见,我们在此还假设每个类别的概率为0.5(each class has probability 0.5)
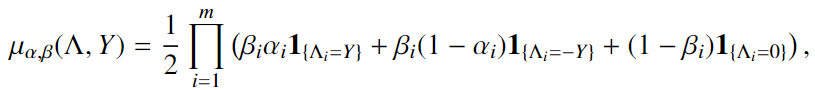
$\Lambda\in\{-1,0,1\}^m$ 包含 labeling functions 输出的标签, $Y\in\{-1,0,1\}$ 是预测的类class
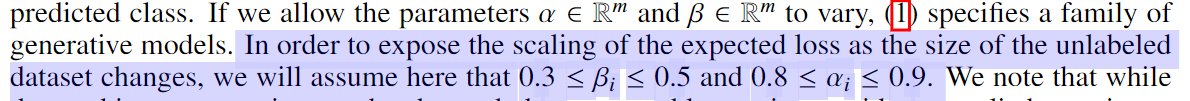
我们注意到,尽管可以更改这些任意约束,但它们与我们的应用经验大致相符,在该经验中,用户倾向于编写高精度和高覆盖率的标签功能。
我们的首要目标是使用最大似然估计来了解在我们的未标记训练集,哪一组参数(α,β)与我们的观察最一致。——为此,对于特定的训练集$S\subset\chi$,我们将解决问题:
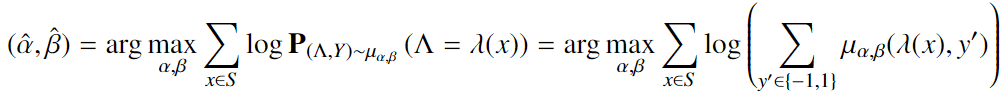
换句话说,我们正在最大化在训练示例中产生的观察到的标签出现在生成模型下的概率maximizing the probability that the observed labels produced on our trainingexamples occur under the generative model in
在我们的实验中,我们使用随机梯度下降法解决了这个问题。由于这是一种标准技术,因此我们将其分析推迟到附录中进行
Noise-Aware Empirical Loss
鉴于我们的参数学习阶段已成功找到一些可以准确描述训练集的$\hat\alpha$和$\hat\beta$,现在,我们可以继续估计参数w(feature mapping的参数矩阵),在给定$\hat\alpha$和$\hat\beta$的情况下,minimizes the expected risk of a linear model over our feature mapping $f$。定义了感知噪声的经验风险noise-aware empirical risk $L_{\hat\alpha,\hat\beta}$, with regularization parameter $\rho$
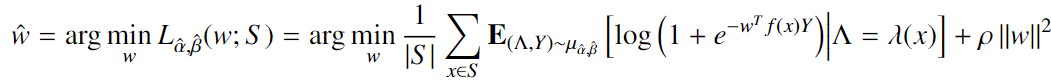
这是一个逻辑回归问题,因此也可以使用随机梯度下降法解决
实际上,我们可以证明在我们现在描述的条件下,在(2)和(3)上运行的随机梯度下降可以保证产生准确的估计:
条件1:
the problem distribution $\pi$ needs to be accurately modeled by some distribution $\mu$ in the family that we are trying to learn, for $\alpha^,\beta^$
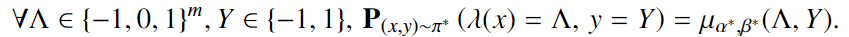
条件2:
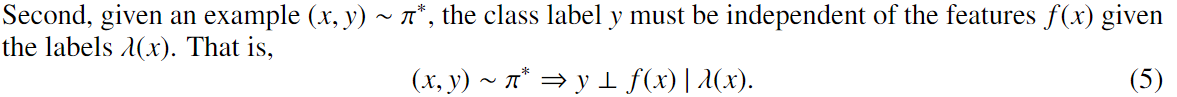
上述条件2约束 labeling functions 可以任意依赖于特征may be arbitrarily dependenton the features,提供足够的信息以准确识别类别 class
条件3:
我们认为用于求解(3)的算法具有有界的generalization risk,$\chi$
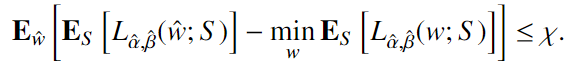
在上述条件下,我们对估计的准确性做出以下陈述

4 Handling Dependencies
随着系统的开发增加了更多的labeling functions ,在标签功能中自然会产生隐式的依赖结构:在某些情况下,对这些依赖进行建模可以提高准确性。我们描述了一种方法,用户可以通过该方法将这种依赖关系知识指定为依赖关系图dependency graph,并说明系统如何使用它来产生更好的参数估计
Label Function Dependency Graph
augment the data programming specification with label function dependency graph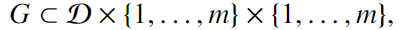 是labeling functions的有向图,每条边是一种commonly-occurring types of dependencies:similar,fixing,reinforcing, andexclusive
是labeling functions的有向图,每条边是一种commonly-occurring types of dependencies:similar,fixing,reinforcing, andexclusive
举例:两个函数$\lambda_1, \lambda_2$ 而$\lambda_2$ 通常仅在
- $\lambda_1$ 也对这个object 打标签
- $\lambda_1, \lambda_2$在标签上存在分歧,
- $\lambda_2$ 打的标签是对的
我们称此为fixing dependency,因为$\lambda_2$修正了$\lambda_1$的错误。
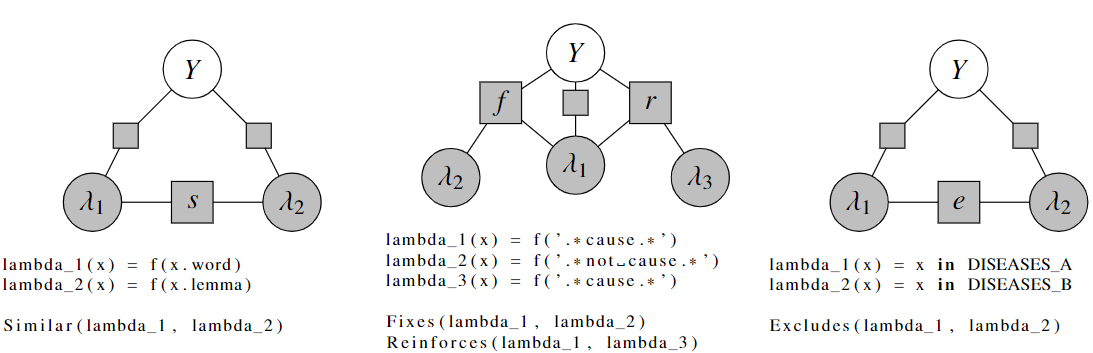
Modeling Dependencie
factor graph建模

对于每个依赖边(d,i,j),我们添加一个或多个factors。

因子图 因子图介绍)
Learning with Dependencies
评价
在这个框架下,用户提供一组Heuristic标注函数(Labeling Functions)。这些标注函数可以互相抵触,可以重复,也可以依赖外部的Knowledge Base等。然后,文章提出的框架则学习各个标注函数之间的Correlation关系,从而可以利用多种标注函数,达到监督学习(Supervised Learning)的效果。
文章采用Logistic Regression在Binary的分类问题上作为一个例子。每一个Heuristic标注函数拥有两个参数,一个是控制有多大可能性标注一个对象,而另一个则是控制标注对象的准确度。于是学习这两个参数就成为目标函数的主要部分。
在所有的标注函数都是独立的情况下,文章采用了最大似然(Maximum Likelihood Estimation)的方法估计到这两个参数的取值。在已经得到了这两个估计的情况下,作者们进一步利用原本的Logistic Regression来学习一个分类器。也就是说,整个框架分为两个部分。
当然,独立的标注函数作用还是有限。文章提出了一个类似Markov Random Field的方式来处理各个标注函数之间的相互关系。在数据实验中,基于Data Programming的方法不管是在人工Feature还是采取LSTM自动学习的Feature中都有很显著的效果提升。这篇文章非常适合需要对Crowdsourcing进行学习和研究的学者。