『Snorkel— rapid training data creation with weak supervision』阅读笔记
- 早期版本的Snorkel的问题之一是用户难以在一个模型中应用不同的标签来源。通过在标签功能(LF)周围创建一层接口以及特定语言来表达这些功能的不同种类,可以解决此问题——。用户可以自实现标注函数,也可以用snorkel提供的接口,包括:正则、远程监督、弱分类器以及标注函数生成器。
- 用生成模型学习weak supervision sources 的准确性,而且能够学习其依赖性和相关性。
- 通过label density作为是否选择使用生成模型的依据,middle-density most benefit from applying the generative model
- automatically choose a value of that trades-off between predictive performance and computational cost——包含多少的LF相关 correlation threshold
- 主要通过一个 running example 解释snorkel的运行过程:
- Data Model:context hierarchy的数据结构,以parent/child relation存储在关系数据库中。
- 可以手动编写Labeling Functions或是使用Snorkel includes 的library of declarative operators
- Pattern-based:higher information density input
- Distant supervision
- Weak classifiers:limited coverage, noisy, biased, and/or trained on a different dataset—can be used as labeling functions
- Labeling function generators:generate multiple labeling functions from a single resource,such as crowdsourced labels and distant supervision from structured knowledge bases
专有名词
- Spans of text——文本跨距
- 生成模型、辨别模型
- 无监督
- 对数似然、对数边际似然
- 迭代随机梯度下降
- 吉布斯采样
- contrastive divergence [23]
- Numbskull library—— Python NUMBA-based Gibbs sampler.
- ablation stud——
摘要
1 Introduction
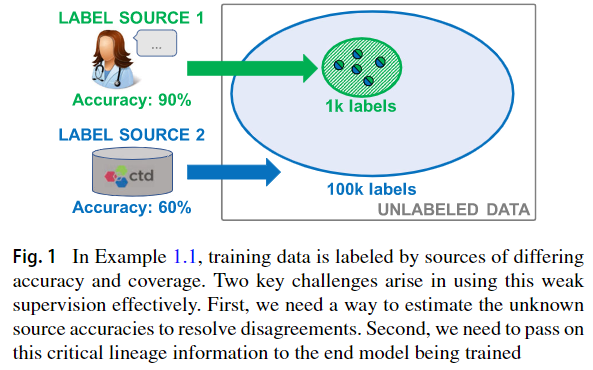
理想情况下,我们将合并许多弱监督来源的标签,以提高训练集的准确性和覆盖范围。但是,有效地进行操作存在两个关键挑战。首先,源 source将重叠和冲突,要解决它们的冲突,我们需要估计其准确性和相关性结构,而又无法获得 ground truth。其次,我们需要将有关标签质量的关键沿袭信息传递给正在训练的终端模型
Fig1:Source1, high-accuracy, low-coverage ; Source2,low-accuracy, high-coverage 。两者在中间的label(分色点处) overlap and disagree 。如果我们以不加权的多数票解决冲突,那么最终将得到无效(并票)标签。如果我们可以正确地估计源准确性,我们将朝源1的方向解决冲突。——在用训练集用于训练end model时,要给high-accuracy sources更大的权重,因此要represent training label lineage
data programming: generating probabilistic training labels representing the lineage of the individual labels—— we can recover source accuracy and correlation structure without hand-labeled training data。这是之前的理论
现在推出Snorkel: the first end-to-end system for combining weak supervision sources to rapidly create training data
提取了三条原则:

我们的工作做出了以下技术贡献:
A Flexible Interface for Sources:
challenge:不同类型的弱监管对输入数据的不同范围进行操作。distant supervision has to be mapped programmatically to specific spans of text. Crowd workers and weak classifiers often operate over entire documents or images. Heuristic rules,他们可以同时利用来自多个上下文的信息,例如将文档标题,文本中的命名实体和知识库中的信息组合在一起。这种异质性非常繁琐。
解决:我们围绕labeling function (LF)的抽象概念构建了一个接口层interface layer
Trade-offs in Modeling of Sources: Snorkel使用生成模型来学习弱监督源的准确性[而不需要用到ground truth43]。此外,它还学习了源之间的相关性和其他统计相关性,并纠正了标注函数中那些会使得估计的准确性产生偏差的相关性correlations。这种范例在预测性能和速度之间产生了以前没探索的trade-off。自然而然的第一个问题是:何时对源准确性进行建模可以提高预测性能?此外,有多少依赖关系(例如相关性)值得建模?
在弱化监督的生成模型中,我们研究预测性能与训练时间之间的权衡。虽然建模源的准确性和相关性不会妨碍预测性能,但我们提出了对简单多数表决simple majority vote何时同样有效的理论分析。根据我们的结论,我们引入了一种优化器,用于确定何时对标签函数的准确性进行建模,以及何时可以跳过学习以进行简单的多数表决。此外,我们的优化器会自动确定标签函数之间的哪些相关性要进行建模。该优化器正确地预测了生成模型过大投票的优势,使平均在我们的评估任务中的投票精度在2.16个准确度点之内,并通过以下方式加快了管道的执行速度1.8倍它还使我们可以获得相关学习优势的60–70%,同时节省多达61%的培训时间(每次执行34分钟)。
First End-to-End System for Data Programming:
2 Snorkel architecture
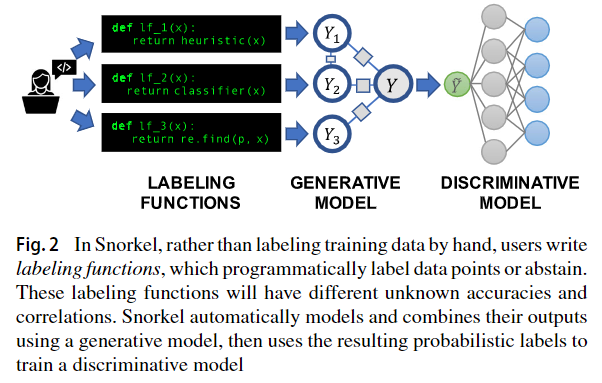
工作流的三个阶段:
- Writing Labeling Functions: 能够使用不同的sources such as patterns, heuristics, external knowledgebases,
- Modeling Accuracies and Correlations:通过标注函数自动学习生成模型,这样就可以估算其准确性和相关性。此步骤不使用任何ground-truth data,,而是从标注函数的 agreements and disagreements 中学习。我们观察到,与未加权标签组合相比,此步骤比Snorkel的最终预测性能提高了5.81%,并且有趣的是,它通过提供有关标注函数质量的可行反馈,简化了用户开发经验。
- Training a Discriminative Model: Snorkel的输出是一组概率标签probabilistic labels,可用于训练各种最先进的机器学习模型,例如流行的深度学习模型。虽然生成模型本质上是用户提供的标签功能的重新加权组合(这些标签功能往往精确但覆盖率较低),但现代判别型模型可以保持这种精度,同时学会推广标签功能之外的其他方面,从而增加了覆盖范围和稳健性看不见的数据。
Setup
目标是学习参数分类模型$h_{\theta}$ ,提供data $x\in\mathcal{X}$,预测label $y\in\mathcal{Y}$
我们将重点放在二元的问题上,尽管我们在实验中包括了多类应用程序。例如,x可能是医学图像,而y是一个标签表示正常与异常。在我们查看的关系提取示例中,我们经常将 x 称为候选对象。在传统的监督学习设置中,我们将通过将其拟合到一组训练有标记的数据点来学习hθ。但是,在我们的设置中,我们假设我们只能访问未标记的数据进行培训。我们确实假设可以访问开发过程中使用的一小部分标记数据(称为开发集)和还有一个访问不到的,带有标签的测试集以进行评估。这些集合的大小可以比训练集合小几个数量级,从而使它们的获得很经济。
Snorkel旨在通过提供一组标注函数(黑盒函数)来生成训练标签:$\lambda:\mathcal{X}\rightarrow\mathcal{Y}\cup\{\emptyset\}$use ∅ to denote that the labeling function abstains放弃
Given m unlabeled data points and n labeling functions, Snorkel 将标注函数应用于未标记的数据,以生成标注函数输出矩阵 $\Lambda\in(\mathcal{Y}\cup\{\emptyset\})^{m\times n}$
剩下的工作是将这个label标签矩阵 $\Lambda$ (可能包含每个数据点的重叠和冲突标签)合成为一个概率训练标签向量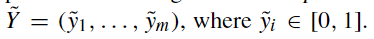 然后,可以使用这些训练标签来训练判别模型
然后,可以使用这些训练标签来训练判别模型
文本关系提取任务的运行示例,可以作为许多现实世界中的知识库构建和数据分析任务的代理
考虑从生物医学文献中提取不良化学疾病关系的提及的任务,给定带有化学药品和疾病标签的文件,我们将每个co-occurring (chemical, disease) 提及对称为“候选提取物”,我们将其视为数据点用于分类为真或假

Data Model
一个设计挑战是管理复杂的,非结构化的数据,使中小企业能够在其上编写标注函数。在Snorkel中,输入数据存储在上下文层次结构context hierarchy中。它由通过父/子关系连接的上下文类型组成 context types connected by parent/child relationships,,这些上下文类型存储在一个关系数据库中,并且可以通过使用SQLAlchemy构建的对象关系映射 object-relational mapping(ORM)层来使用。每个context type表示的是系统要处理或使用的数据的概念性组成部分当在编写标注函数时;例如文档,图像,段落,句子或嵌入式表格。然后将候选对象(即数据点x)定义为上下文元组。
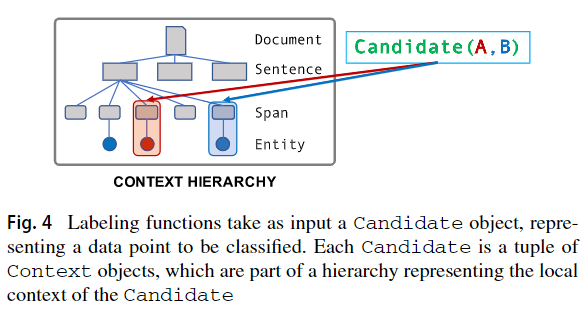
在我们正在运行的CDR示例中,输入的文档可以在Snorkel中表示为由文档组成的层次结构hierarchy consisting of Documents,每个文档包含一个或多个句子Sentences,每个文档包含一个或多个文本跨距Spans of text.也可以用元数据标记这些跨距Spans,例如实体标记将其标识为化学或疾病的表态such as Entity markers identifying them as chemical or disease mentions 。 A candidate is then a tuple of two Spans.
2.1 A language for weak supervision
Snorkel使用标注函数的核心抽象来允许用户指定各种弱监督源,例如patterns, heuristics, external knowledge bases, crowdsourced labels, 等。如后面的部分所述,这种较高级别higher-level,,精度较低的输入提供的效率更高(请参见第4.2节),并且可以自动去噪和合成。
因此,我们允许用户在两个抽象级别上编写标签函数:自定义Python函数和声明性运算符——: custom Python functions and declarative operators.,从而权衡了表达性和效率
Hand-Defined Labeling Functions
input: Candidate object
output: a label or abstains
这些函数通常类似于extract–transform–load scripts,表达基本模式或启发式方法patterns or heuristic,但可能会使用支持的编码器 supporting code 或者 资源,并且会很复杂。
这些函数是写在ORM 层——它将上下文层次结构和关联的元数据associated metadata映射为面向对象的语法,从而允许用户轻松遍历输入数据的结构
以上面一直举出的例子来说明

Declarative Labeling Functions
Snorkel包含一个声明性运算符库,该运算符库根据我们去年与用户的经验对最常见的weak supervision函数类型进行编码
这些操作符的语义和语法 semantics and syntax易于使用,并且可以轻松自定义,包括以下两种主要类型
- labeling function templates:输入一个或多个参数,并输出一个 labeling function;
- labeling function generators:它接受一个或多个参数,并输出一组标记函数(如下所述)。这些功能捕获了一系列常见的弱监督形式,例如
- Pattern-based For example, pattern-based heuristics encompass feature annotations [64] and pattern-bootstrappingapproaches [19,22] (Example2.3)
- Distant supervision Distant supervision generates training labels by heuristically aligning data points with anexternal knowledge base and is one of the most popularforms of weak supervision [3,24,36]
- Weak classifiers Classifiers that are insufficient for our task—e.g., limited coverage, noisy, biased, and/or trainedon a different dataset—can be used as labeling functions.
- Labeling function generators One higher-level abstraction that we can build on top of labeling functions inSnorkel islabeling function generators, which generate multiple labeling functions from a single resource,such as crowdsourced labels and distant supervision from structured knowledge bases (Example2.4).
Example2.4 —— Labeling function generators
传统 distant supervision遇到的问题是:知识库的不同子集具有不同的准确性和覆盖范围

Interface Implementation
Execution Model
由于标注函数在离散的候选对象上运行,它们的执行是并行的。如果连接到一个关系型数据库提供同时连接,例如PostgreSQL,然后主进程(通常是笔记本内核)将候选主键分配给Python工作进程。工作人员独立地从数据库中读取,通过ORM层实现候选人,然后在他们上面执行标记功能。标签被返回给主进程,主进程通过ORM层保存它们。由于表级锁定,在主服务器上收集标签比让工人直接写入数据库更有效。Snorkel包含一个Spark集成层,允许在集群中运行标记函数。一旦候选集被缓存为Spark数据帧,只需要关闭标签功能和产生的标签需要与工人沟通。这在Snorkel的迭代工作流中特别有用。跨集群分布大型非结构化数据集的成本相对较高,但只需执行一次。然后,随着用户改进他们的标签功能,他们可以有效地重新运行。
如果连接到一个关系型数据库提供simultaneous connections, e.g., PostgreSQL,then the masterprocess (usually the notebook kernel) distributes the primary keys of the candidates to be labeled to Python worker processes. The workers independently read from the database to materialize the candidates via the ORM layer, then executethe labeling functions over them. The labels are returned to the master process which persists them via the ORM layer.Collecting the labels at the master is more efficient than having workers write directly to the database, due to table-level locking.Snorkel includes a Spark integration layer, enabling labeling functions to be run across a cluster. Once the set of candidates is cached as a Spark data frame, only the closure of the labeling functions and the resulting labels need to be communicated to and from the workers. This is particularly helpful in Snorkel’s iterative workflow. Distributing a large unstructured data set across a cluster is relatively expensive,but only has to be performed once. Then, as users refine their labeling functions, they can be rerun efficiently。
2.2 Generative model
The core operation of Snorkel is modeling and integrating the noisy signals provided by a set of labeling functions.
我们将数据点的真实类标签rrue class label 建模为概率模型中的隐变量。在最简单的情况下,每个labeling functions都看成是独立的投票,错误labeling是和其他labeling functions不相关的。这将标注函数的投票的生成模型定义为 noisy signals about the true label.
对上面简单的改进,我们还可以对标记函数之间的统计依赖性tatistical dependencies进行建模,以提高预测性能。如果两个标记函数express similar heuristics,我们可以在模型中包括这种依赖性,从而避免出现“重复计算double counting”问题。我们观察到这种成对的相关性是最常见的,因此我们在本文中重点介绍(尽管处理高阶相关性很简单)。我们将我们的结构学习方法[5]用于这个生成模型,以选择a set C of标记函数对(j,k)来建模成 相关模型model as correlated。

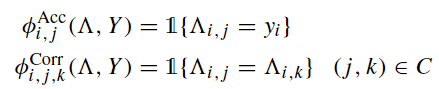

因子图建模,包括多种relation的因子函数,对LFs给出的标注向量做最大似然估计,采用对和真实标注—隐变量的边际概率
2.3 Discriminative model
Snorkel的最终目标是训练一种模型,该模型可以对标注函数中表达的信息进行泛化。

正式分析表明,随着我们增加未标记数据的数量,使用Snorkel训练的判别模型的泛化误差将以与传统监督学习模型对其他手工标记数据相同的渐近率降低[43],从而使我们能够通过以下方式提高预测性能:添加更多未标记的数据。从直觉上讲,此属性成立是因为随着提供更多数据,判别模型会看到更多与标记功能中编码的启发式同时出现的功能。
Example 2.5“ Myasthenia gravis presenting as weakness after magnesium administration.” 我们开发的33个标注函数中没有一个对$Causes(magnesium,myasthenia gravis)$ 投票, 都abstain
然而,经过Snorkel概率训练标签probabilistic training labels训练的深度神经网络可以正确地将其识别为正确的提及true mention。Snorkel为流行的机器学习库(如TensorFlow [1])提供了连接器,使用户可以利用商品模型,例如不需要人工设计特征的深度神经网络。并在各种任务中具有强大的预测性能
3 Weak supervision trade-offs
我们研究了一个基本问题,即何时以及以何种复杂程度期望Snorkel的生成模型能够最大程度地提高预测性能。了解这些性能机制可以帮助指导用户,并在预测性能和速度之间进行权衡。我们将这个空间分为两个部分:首先,通过分析何时可以通过未加权多数票unweighted majority vote来近似生成模型;其次,通过自动选择要建模的相关结构的复杂度。然后,我们引入了一个基于规则的两阶段优化器,以支持快速的开发周期。
3.1 Modeling accuracies
3.1.1 Trade-off space
considering the label density标签密度 $d_{\varLambda} $of the label matrix${\varLambda} $定义为每个数据点非弃权标签的平均数量。当标签密度低时,标签的稀疏性意味着即使对标签功能进行最佳加权,与he majority vote 比较也很有限。 It is the middle density regime where we expect to most benefit from applying the generative model.
我们以labeling 的 true accuracies来度量the benefit of weighting the labeling functions 对比an unweighted majority vote——true accuracies是指the predictions of a perfectly estimated generative model


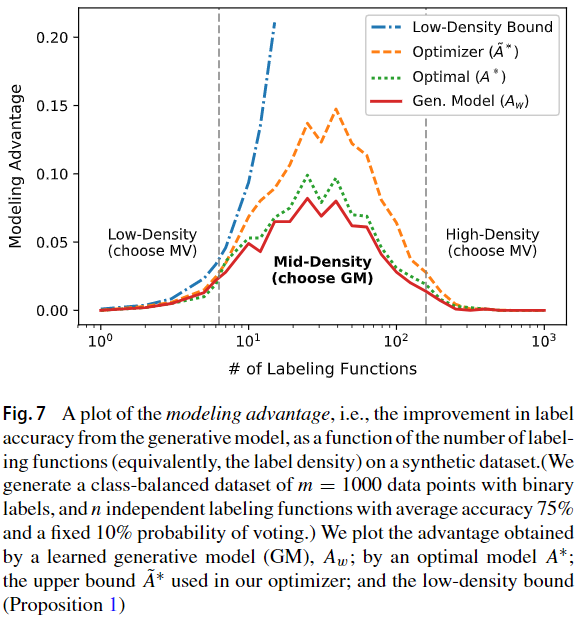
Low Label Density——在这种稀疏设置中,很少有数据点具有不止一个non-abstaining 标签。只有少数具有多个冲突标签——证明此情况下的upper bound
High Label Density——大多数数据点具有大量标签——比如,我们可能会在极大量的众包环境中工作,或者在具有许多高覆盖率知识库的应用程序中进行远程监管——证明此情况下的upper bound
Medium Label Density——在这种中间状态下,我们期望对标签函数的准确性进行建模将在预测性能方面带来最大的收益,因为我们将拥有许多带有少量不同标签函数的数据点。对于这样的点,估计的标记函数准确性会严重影响预测的标记。我们确实看到,使用仅包含准确度因子$φ_{i,j}^{Acc}$,j的独立生成模型,经验结果有所提高(表1)。此外,[43]中的保证确立了我们可以学习最优权重,从而获得最优优势。
3.1.2 Automatically choosing a modeling strategy
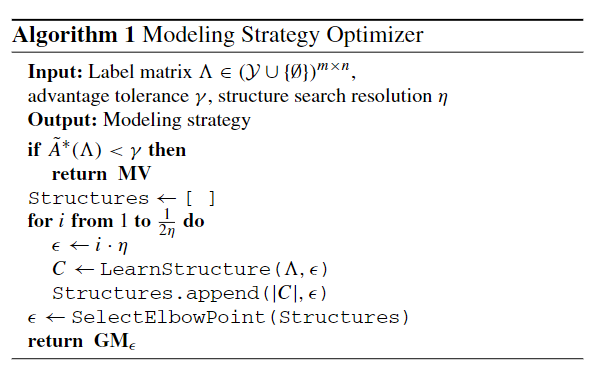
The bounds in the previous subsection imply that there are settings in which we should be able to safely skip modeling the labeling function accuracies, simply taking the unweighted majority vote instead.
整体标签密度 $d_{\varLambda} $在 given a user time-cost trade-off preference (characterized by the advantage tolerance parameterγ in Algorithm1)的精确度不足以确定目标转换点determine the transition points of interest
除了查看 $d_{\varLambda} $,相反,我们通过查看每个数据点的正负标签比率来开发最佳案例启发式方法。这种启发式方法可以作为true expectedadvantage的上限,因此,我们可以使用它来确定何时可以安全地跳过训练生成模型

3.2 Modeling structure
在本小节中,我们将考虑在独立模型之外建模其他统计结构。我们研究了预测性能和计算成本之间的折衷,并描述了如何在此折衷空间中自动选择一个好点。

消除这种依赖性很重要,因为它们会影响我们对真实标签的估计。考虑一种极端的情况,其中不考虑依赖项会造成灾难性的后果:

3.2.1 Trade-off space
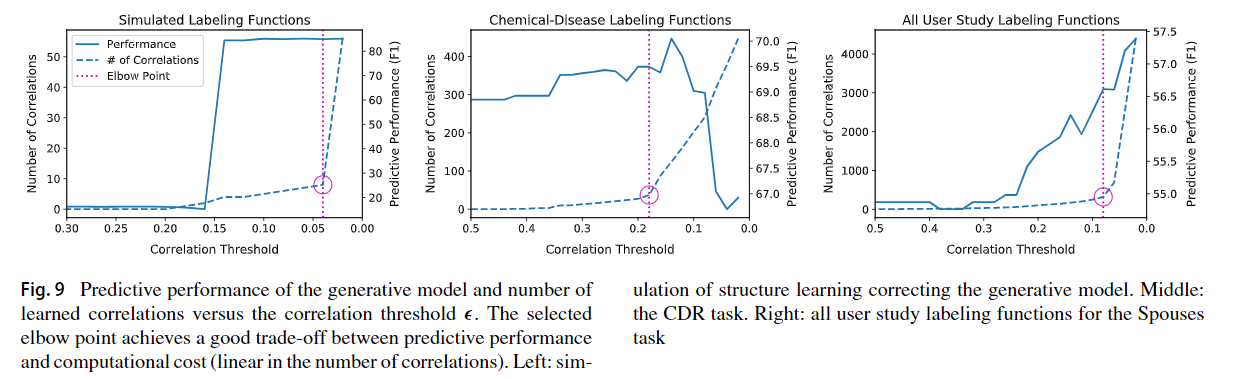
我们研究了预测性能与由此引起的计算成本之间的取舍。我们发现,通常存在一个“肘点”,超过这个“肘点”“elbow point”,选择的相关数he number of correlations selected(从而导致计算成本)爆炸,并且该点是预测性能和计算时间之间的安全折衷点
Predictive Performance
在一个极端情况下,很大的 $\varepsilon$ 值将不会在生成模型中包含任何相关性,从而使其与独立模型相同。减少,将添加相关性。
因为编写的标注函数存在大量冗余
Computational Cost
计算成本与模型复杂度相关。在Snorkel中进行的学习是通过Gibbs采样器完成的,对其他相关建模的开销在相关数量上是线性的
3.2.2 Automatically choosing a model
我们力求仅使用标注函数的输出 $\Lambda$ 来自动找到 $\varepsilon$ 在预测性能和计算成本之间进行权衡。将$\varepsilon$ 设置在“elbow point”是安全的权衡,在预测性能最终下降(中间)的情况下,肘点也会选择相对较少的相关性,从而使F1点提高0.7,并避免过拟合。
4 Evaluation
4.1 Applications
Discriminative Models
为了更好地利用powerful, open source machine learning tools ,Snorkel为具有标准损失函数的任何判别模型创建概率训练标签。

测试的结论:
判别模型的适用范围超出了标记函数中编码的启发式方法
DataSet Details
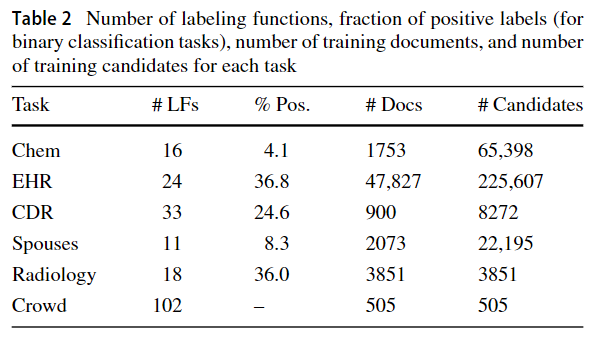
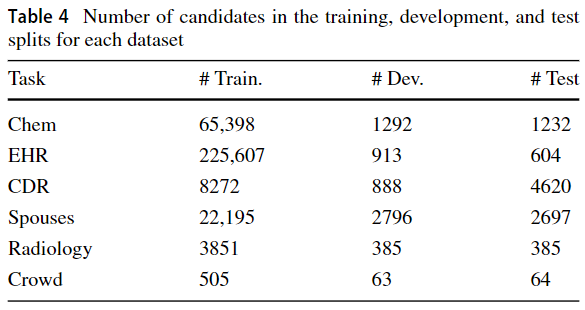
4.1.1 Relation extraction from text
Scientific Articles (Chem)
Electronic Health Records (EHR)
Chemical–Disease Relations (CDR)
Spouses
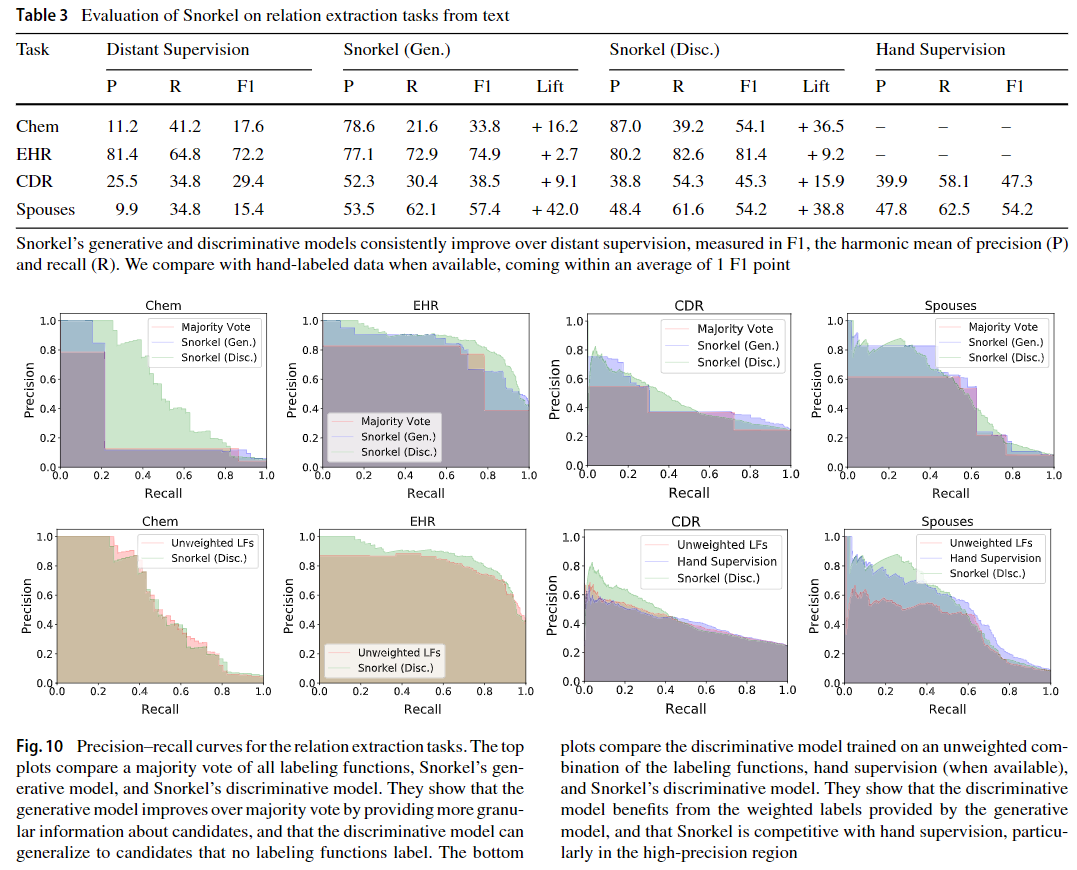
4.1.2 Cross-modal: images and crowdsourcing
我们在一个数据模式(例如a text report, or the votes of crowd workers))上编写标签函数,并使用结果标签来训练在完全独立的第二个模式(例如an image或tweet文本)上定义的分类器。
Abnormality Detection in Lung Radiographs (Rad)
在许多现实世界的放射学环境中,都有大量的图像数据存储库,带有相应的叙述性文本报告,但是有限的标签或没有标签可用于训练图像分类模型。在此应用程序中,我们与放射科医生合作,在文本放射学报告上编写了标签功能,并使用得到的标签来训练图像分类器以检测肺部X射线图像中的异常。我们使用了来自OpenI生物医学图像库15的公开可用数据集,该数据集由3,851个不同的放射学报告(由非结构化文本和医学主题词(MeSH)16代码组成)以及随附的X射线图像组成。
Crowdsourcing (Crowd)
训练了一个模型,使用来自Crowdflower的天气情感任务中的众包注释进行情感分析。在此任务中,要求贡献者对与天气相关的不明确推文的情感进行评级,并在五类情感中进行选择。20个贡献者给每个推文评分,但是由于任务困难和缺少人群工作者筛选,工作者标签上存在许多冲突。我们以标签功能代表了每个群众工作人员,展示了Snorkel吸收现有工作的能力
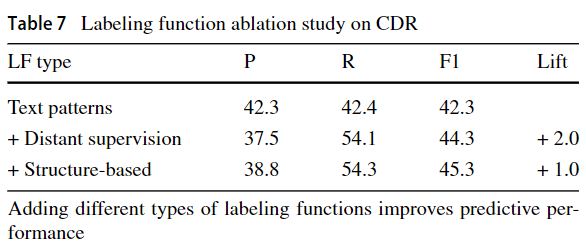
4.1.5 Labeling function type ablation
研究了不同类型的标注函数对最终预测性能的影响
- Text Patterns:Basic word, phrase, and regular expression labeling functions.
- Distant Supervision:External knowledge bases mapped to candidates, either directly or filtered by a heuristic.
- Structure-Based: Labeling functions expressing heuristics over the context hierarchy, e.g., reasoning about position in the document or relative to other candidates.
5 Extensions and next steps
5.1 Extensions for real-world deployments
5.2 Ascending the code-as-supervision stack
由于难以直接在图像或视频数据上编写标签功能,先使用无监督方法在原始数据上先计算a set of features或primitives,然后在这些 building blocks上编写标注函数[58]。例如,如果目标是标记骑乘自行车的实例,则我们可以先运行一种现成的预训练算法,将 bounding boxes 放置在人和自行车周围,然后在这些边界框的 dimensions 或relative locations上编写标记函数。
在医学成像任务中,解剖学分割蒙版 anatomical segmentation masks 为写入标记函数提供了相似的直观语义抽象。例如,在来自UK Biobank的大量心脏MRI视频中,创建了主动脉的分割使心脏病专家能够定义标签功能来识别罕见的主动脉瓣畸形[17]。
甚至更高级别的界面是自然语言。BabbleLabble项目[20]接受数据点的自然语言解释 natural language explanations of data points,然后使用语义解析器 semantic parsers 解析这些explanations 到labeling functions.。这样,没有编程知识的用户仅通过解释数据点为何具有特定标签的原因就具有编写标注函数的能力。另一种相关方法是使用程序合成技术,结合少量标记的数据点,以自动生成标记功能