『Learning Named Entity Tagger using Domain-Specific Dictionary——AutoNER』阅读笔记
为解决标注数据不足问题,通常可以找相似领域的有标记数据做领域迁移、用领域词典做远程监督生成标记数据——本文讨论如何使用领域词表来生成标注数据。用词表直接匹配的问题是:
- 词典无法覆盖所有实体
- 相同实体对应多个类别的情况(缺少上下文),或是遇到词表中不存在的类别
(在 entity span中做,包含共指消解吗)
先提出了解决传统 CRF 无法做多标签分类,现有模型无法解决entity 多label问题的Fuzzy-LSTM-CRF with Modified IOBES:
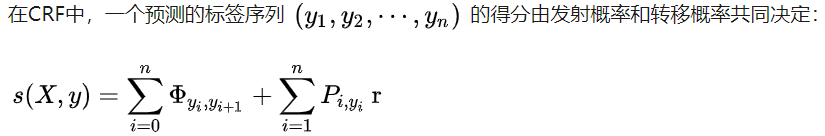

提出了一种 Tie or Break 的标注方案
- 若当前词与上一个词在同一个实体内 Tie (O)
- 若其中一个词属于一个未知类型的实体短语,则该词的前后都是 Unknown (U)
- 其它情况都默认 Break (I)
- 某个实体类型未知 None (N)
实体边界的远程监督信息和实体类别的远程监督信息是分开来计算的。这是为了能充分利用非领域词典——高质量短语词表中的词的边界信息。
模型使用的是一个用 Highway network 优化的 BiLSTM 来做 span prediction
Abstract
深度神经模型的最新进展允许我们构建没有手工特征的可靠命名实体识别 reliable named entity recognition(NER)系统。但是,此类方法需要大量的手动标记训练数据。已经有用远程监督(与外部词典一起)替换人类注释的方法,但是生成的嘈杂标签对学习有效的神经模型提出了重大挑战。在此,我们提出两种神经模型来适应字典中的嘈杂远程监督。首先,在traditional sequence labeling framework下,我们提出了一种修正的模糊CRF层来处理tokens with multiple possible labels。在确定了远程监管中的嘈杂标签的性质之后,我们提出了神经模型AutoNER,具有新的$\text{Tie or Break}$ 方案。此外,我们还讨论了如何优化远程监管为更好的NER性能。在三个基准数据集上进行的大量实验表明,仅使用字典dictionary就可以实现AutoNER的最佳性能,而无需付出额外的人力,并且使用最新的监督基准可以提供具有竞争力的结果
1 Introduction
最近,在构建没有手工特征的可靠命名实体识别(NER)模型方面已进行了广泛的努力。然而,大多数现有方法需要大量的人工注释语句来训练监督模型(例如神经序列模型)(Liu等人,2018; Ma和Hovy,2016; Lample等人,2016; Finkel等人,2005)。这在特定的域下尤其具有挑战性,因为domain-expert annotation is expensive and/or slow to obtain。
为了减轻人类的努力,已应用了远程监管来自动生成标记数据,并已在各种自然语言处理任务中获得成功,包括短语挖掘(Shang等人,2018),实体识别entity recognition(Renet等人,2015; Fries等人)(2017; He,2017),方面项提取aspect term extraction(Giannakopoulos等,2017)和关系提取relation extraction(Mintz等,2009)。同时,开放式知识库(或词典)正变得越来越流行,例如通用领域的 WikiData 和YAGO,以及生物医学领域的MeSH和CTD。这样的词典的存在使得有可能大规模生成 NER 的训练数据而无需额外的人工。
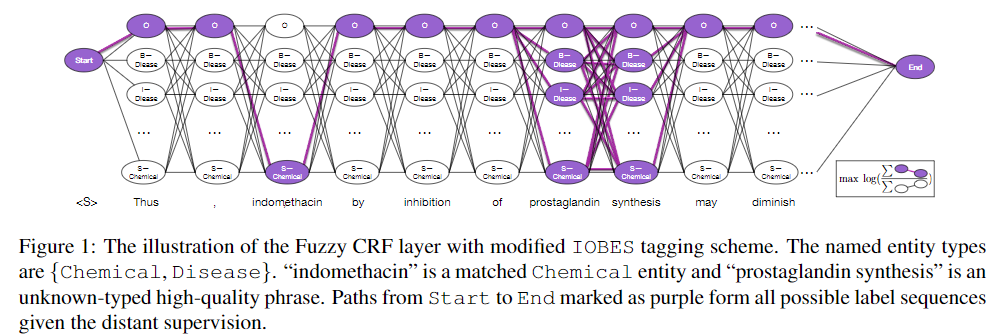
现有的远程监督的 NER 模型通常通过启发式匹配规则来解决实体文段检测entity span detection 问题,例如基于POS标签的正则表达式regular expression(Ren等,2015; Fries等,2017)和精确的字符串匹配exact string matching(Giannakopoulos等,2017; He,2017)。在这些模型中,每个不匹配的token 都将被标记为非实体non-entity。但是,由于大多数现有词典对实体的覆盖范围有限,因此简单地忽略不匹配的标记可能会引入假阴性的labels(例如,图1中的“前列腺素合成”)。因此,我们建议从语料库中提取高质量的out-of-dictionary phrases,并将其标记为具有特殊“未知”类型的潜在实体 potential entities with a special “unknown” type。而且,由于两个不同类型的实体可以在字典中共享相同的表面名称。,因此可以用多种类型标记每个实体范围every entity span in a sentence can be tagged with multiple types, 。为了解决这些挑战,我们用两个带有自定义标记方案 customized tagging schemes来对两个网络模型结构进行比较。
我们从在传统序列标签框架下调整模型 traditional sequence labeling framework开始。NER模型通常基于条件随机场(CRF)用$\text{IOB}$ 或者$\text{IOBES}$ tagging scheme,但是,这种设计不能处理 multi-label tokens. ($\color{red}{传统CRF不能解决多标签标注问题}$) 因此,我们将LSTM-CRF中的常规CRF层(Lample等,2016)自定义为Fuzzy CRF层,该层允许每个tokentoken 具有多个标签而不会牺牲计算效率。
为了适应远程监督生成的不完善标签imperfect labels,提出了一种新的预测模型prediction model。具体而言,我们建议预测两个相邻token是否在相同的实体提及中绑定 tied in thesame entity mention or not(即broken),而不是预测每个单个token的标签。 The key motivation is that, even the boundaries of an entity mention are mismatched by distant supervision, most of its inner ties are not affected, and thus more robust to noise。因此,我们设计了一种新的$\text{Tie or Break}$ 方案,以更好地利用嘈杂的远程监督。因此,我们设计neural architecture 首先通过forms all possible entity spans by detecting such ties,,然后识别每个span的实体类型。$\text{Tie or Break}$ 方案和neural architecture form我们的新模型AutoNER,在我们的实验中,它被证明比Fuzzy CRF模型更好地工作。
贡献
- AutoNER:$\text{Tie or Break}$ 方案和neural architecture ,for the distantly supervised NER task
- Fuzzy-LSTM-CRF model: strong distantly supervised baseline
- refine distant supervision for better NER performance:incorporating high-quality phrases to reduce false-negative labels,进行了消融实验
2 Overview
我们的目标是使用且仅使用字典来学习命名实体。每个字典条目均包含以下内容:1)实体的表面名称surface name,包括其规范名称和同义词的列表;2)实体类型。考虑到词典的覆盖范围有限,我们通过添加高质量的短语high-quality phrases作为类型未知的潜在实体来扩展现有的词典
给定一个原始的语料库raw corpus 和字典,我们首先通过精确的字符串匹配 string matching生成实体标签 entity labels (包括未知的labels),其中冲突匹配通过最大化匹配标记的总数来解决 conflicted matches are resolved by maximizing the total number of matched tokens(Etzioni等,2005; Hanisch等,2005;Lin et al。,2012; He,2017)
根据字典匹配dictionary matching的结果,每个tokentoken都属于以下三类categories之一:1)它属于具有一种或多种已知类型types的实体提及 entity mention;2)属于未知类型的实体提及;3)标记为非实体。
3 Neural Models
3.1 Fuzzy-LSTM-CRF with Modified IOBES
under the traditional sequence labeling framework
State-of-the-art named entity taggers使用$\text{IOB}$ 或者$\text{IOBES}$ 标注集,为sequence labeling framework(Ratinov和Roth,2009年),因此需要CRF层来捕获 输出标签 之间的依赖性dependency between labels。但是,原始方案和常规CRF层都不能处理多类型或未知类型的tokentokens。因此,我们相应地提出了改进的IOBES方案和Fuzzy CRF层
Modified IOBES
为了减少标注成本,文中采用Distant-supervision方法进行标注,即预先收集需要识别的实体词典库,采用词匹配的方法,在待处理文本中将词典中匹配到的实体标记出来。标注方法如下:
我们根据三个token类别定义标签:
- 如果一个token标记为一种或多种类型,则这个token用所有这些types和$\{\text{I,B,E,S}\}$中的一种,according to its positions in the matched entity mention
- 类型未知的token,即词典中未出现的词,但属于词典中的高质量短语 high quality phrase。$\{\text{I,O,B,E,S}\}$所有五个都有可能,同时,分配了所有可用的类型。例如,如果只有两个可用types Chemical和Disease,则总共有2*4+1=9中labels ,但要注意 $\{\text{I,O,B,E,S}\}$的标注顺序,比如B的后面不能再跟一个B
- 对于标记为非实体的token,其标记$\{\text{O}\}$

Fuzzy-LSTM-CRF
我们将LSTM-CRF模型(Lample等,2016)修改为Fuzzy-LSTM-CRF模型,以支持修改后的IOBES标签。
输入:一个word sequence $X_1,X_2,…,X_n$
它首先通过单词级 word-level BiL-STM(forward and backward LSTMs)
在串联了两个方向输出的 representations后,该模型为每个输出标签做出独立的标记决策——输出分数$P_{i,y_j}$——the word $X_i$ being the label $y_j$
我们遵循先前的工作(Liu等人,2018; Maand Hovy,2016; Lample等人,2016)来定义预测序列的得分,预测序列 $y_1,y_2,…,y_n$ 的得分。其中,$\phi_{y_i,y_{i+1}}$ 是从label $y_i$ 到 label $y_{i+1}$ 的转移概率,$\phi$ 是$(k+2) \times (k+2)$ 大小的矩阵,Two additional labels start and end are used (only used in the CRF layer) to represent the beginning and end of a sequence, respectively
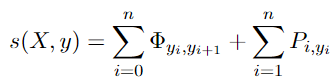
传统的CRF层将唯一有效标签序列 only valid label sequence的可能性最大化,只需要最大化一条标注路径的概率即可,但在修改的IOBES方案中,一个句子可能具有多个有效的标签序列,由于存在多条路径,那么我们就需要同时最大化所有路径的概率,因此,我们将常规CRF层扩展为模糊CRF模型fuzzy CRF model。
它枚举IOBES标签和所有匹配的实体类型,Objective是最大化所有可能的标签序列的总概率。优化目标:

在训练过程中,we maximize the log-likelihood function of上式
S:路径得分,计算方法与传统的CRF相同
the state-of-the-art distantly supervised phrase mining method :AutoPhrase (Shanget al., 2018)
预标注中提到的高质量短语(high quality phrases),我们通过AutoPhrase的方法从文本中挖掘(论文:Automated phrase mining from massive text corpora,代码:AutoPhrase)通过ulabeled语料和短语词典,设置适当的阈值,我们可以挖掘出高质量的短语。对于挖掘出来的短语,如果没在词典中出现过,我们就把它加入单独的一个“unknown”词典。
3.2 AutoNER with “Tie or Break”
着眼于相邻tokens之间的联系ties,即它们 are tied in the same entity mentions or broken into two parts。因此,我们为此方案设计了一种新颖的神经模型
“Tie or Break” Tagging Scheme
具体来说,对于每两个相邻的tokens,它们之间的连接标记为
- Tie: 当两个token与同一实体匹配时,属于同一个实体mention即前后两个token构成一个实体mention
- Unknown: if at least one of the tokens belongs to an unknown-typed high-quality phrase;
- 否则为 Break
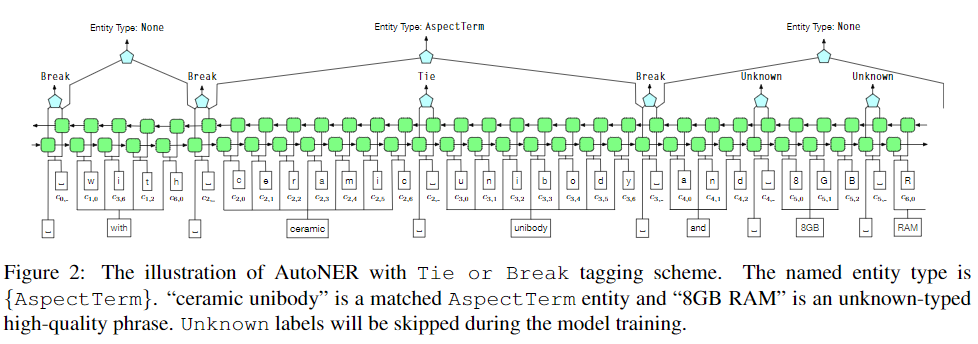

distant-supervision指出“ceramic unibody”匹配到了AspectTerm词典,8GB RAM是一个unknown高质量短语。因此ceramic unibody之间就被标记为Tie,短语8GB RAM的前后和中间就标记为Unknown。两个连续的Break标记之间的tokens就形成了一个span,每一个span都将被打上标签集中的所有匹配上的标签(词典匹配)。如果没有匹配到实体类型,我们就将其标记为None
AutoNER
在“Tie or Break” Tagging Scheme中,entity spans and entity types are encoded into two folds. Therefore, we separate the entity span detection and entity type prediction into two steps.
实体span和type分两步编码,将实体span检测和实体类型预测分为两步执行。
- entity span detection:在预测span序列时,只预测是tie还是break,在计算损失时,忽略真实为Unknown的token。而在计算type损失的时候,包括了序列中所有的token。构建一个二元分类器,输出类别为Break和Tie;如果预标注是Unknown类型则直接跳过。在第i个token和它的前一个token间,将BiLSTM 的输出串联得到一个新的特征向量 $u_i$ ,被输入一个 sigmoid 层,估计这里是一个 Break 的概率

- entity types: BiLSTM的输出将 re-aligned 以形成一个新的特征向量 $v_i$ , for $i th$ span candidate。 $v_i$ 会被输入softmax layer,输出 $v_i$ 在每个实体类别上的概率,估计entity type分布为
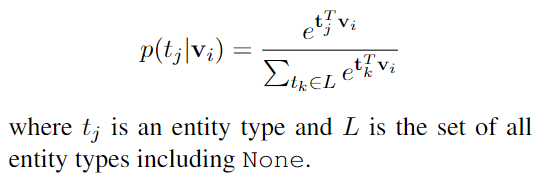
由于 one span 可以被标记为多种类型,我们将 possible set of types for $i th$ entity span candidate 的可能类型标记为 $L_i$,第i个span 的 候选实体类型集


因为无明确的监督信息,因此采用,可能type集合内的概率分布作为监督信息,使得概率主要分配在可能的type集合上而不是整个type集中
AutoNER 没有 CRF 层和 Viterbi 解码,则在 inference 时更加高效
3.3 Remarks on “Unknown” Entities
“Unknown”实体提及 不是其他类型的实体,而是我们对它们的边界不太确定和/或无法根据远程监管来识别其类型的tokenless confident about their boundaries and/or cannot identify their types based on the distant supervision。例如,在图1中,“prostaglandin synthesis”是“Unknown”的 token span。 distant supervision无法确定它是 Chemical 还是 Disease,是其他类型的实体,是两个单独的single-token entities还是(部分)不是实体?因此,在FuzzyCRF模型中,我们为这些标记分配了所有可能的标签。
在我们的AutoNER模型中,这些“Unknown” positions具有undefined boundary and type losses,原因是:(1)它们使边界标签不清楚make the boundary labels unclear;以及(2)没有类型标签 type labels。由于边界的标签和实体类型都是unknown,在训练时它们被跳过。
4 Distant Supervision Refinement
完善远程监管的两种技术,以更好地命名实体标签——都是说字典匹配
4.1 Corpus-Aware Dictionary Tailoring词典裁剪
在字典匹配中,盲目使用完整词典可能会引入假阳性标签,因为存在许多超出给定语料库范围的实体,但它们的别名可以匹配。
例如,当字典中具有不相关的字符名称“ Wednesday Addams” 及其别名“ Wednesday”时, many Wednesday’s will be wrongly marked as persons。在理想情况下,词典应覆盖并且仅覆盖给定语料库中出现的实体,以确保在保持合理覆盖率的同时确保较高的精度。
作为近似,我们通过排除规范名称从未出现在给定语料库中的实体,将原始词典调整为与语料库相关的原始词典子集。背后的直觉intuition是,为了避免歧义,人们可能会至少提及一次实体的规范名称。(当说到某个实体对象时,人们至少会提起一次其正式的名称。因此,我们删除词典中那些正式名称从来没有出现过的实体(包括其别名),将能有效降低误召回。)例如,在生物医学领域,分别对BC5CDR和NCBI数据集中提到的实体的88.12%,95.07%成立,即至少提及一次canonical name。我们期望与在原始字典上训练的 NER model 相比,在这种调整后的字典的subset上训练的 NER model 具有更高的精度和合理的召回率
4.2 Unknown-Typed High-Quality Phrases
远程监管的另一个问题是关于假阴性标签false-negative labels。当token span无法与词典中的任何entity surface names匹配时,由于词典的覆盖范围有限,仍然很难确定其为非实体(即否定标签)。具体来说,一些字典范围之外的高质量短语 high-quality phrases 也可能是潜在的实体。
We utilize the state-of-the-art distantly supervised phrase mining method, AutoPhrase (Shanget al., 2018)。 以给定域中的语料库和字典作为输入,AutoPhrase仅需要未标记的文本和高质量短语的词典。我们通过设置阈值来获得高质量的多词和单词短语 (e.g., 0.5and 0.9 respectively). 实际上,人们可以从同一域中查找更多未标记的文本(例如,PubMed论文和Amazon笔记本电脑评论),并使用相同的特定于域的词典 执行 NER 任务。在我们的实验中,对于生物医学领域,我们使用从整个 PubTator 数据库中 均匀采样的686,568篇PubMed论文(约4%)的标题和摘要作为训练语料库。对于笔记本电脑评论领域,我们使用Amazon笔记本电脑评论数据集3,该数据集旨在用于aspect-based的情感分析(Wang等人,2011年)
我们将 out-of-dictionary phrases 视为具有“unknown”类型的潜在实体,并将其合并为新的字典条目 incorporate them as new dictionary entries。此后,仅在此扩展词典中无法匹配的 token span 将被标记为 non-entity 。Being aware of these high-quality phrases, we expect the trained NER tagger should be more accurate。(通过这种方法,我们只需要准备大量的目标领域无标签语料和一个高质量的种子词典即可,通过调节posing threshods,我们很容易获取大量高质量的短语数据。我们对些短语数据进行筛选,除去那些在其它词典中出现过的短语,剩下的短语集构成“unknown”词典。在进行远程监督时,只有同时未被实体类型词典和unknown词典匹配的部分才被标记为non-entity。)
5 Experiments
5.1 Experimental Settings
Datasets——corpus

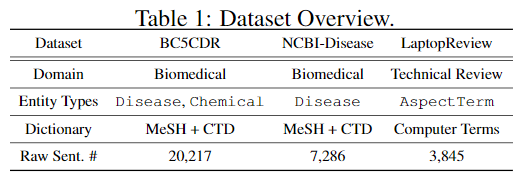
前两个数据集已经划分为三个子集:训练集,开发集和测试集。对于 LaptopReview 数据集,我们遵循(Gian-nakopoulos等人,2017),并从训练集中随机选择20%作为开发集。 Only raw texts are provided as the input of distantly supervised models,而gold training set 用于监督模型.
Domain-Specific Dictionary
对于生物医学数据集,该词典是 MeSH 数据库MeSH和 CTD Chemical and DiseaseCTD 词汇集的组合。该词典包含322,882个 Chemical and Disease entity surfaces。
For the laptop review datasetlaptop review, the dictionary has 13,457 computer terms crawled from a public website
Metric
micro-averaged F1 score
Parameters and Model Training
基于开发集中的分析,我们进行了带有动量的随机梯度下降的优化stochastic gradient descent with momentum。我们将批量大小和动量设置为10和0.9。最初将学习率设置为0.05,如果最近5轮中没有更好的发展F1,则学习率将降低40%。在模型中应用了ratio 为 0.5 的 Dropout 。为了获得更好的稳定性,我们使用 5.0 的梯度剪切 gradient clipping 。此外,我们在开发集中采用了early stopping
Pre-trained Word Embeddings
对于生物医学数据集,我们使用来自(Pyysalo等人,2013)的预训练的200维单词向量biomedical datasets,这些向量在整个 PubMed abstracts,PubMed Central(PMC)的所有全文文章和英语 Wikipedia 上进行了训练。
对于笔记本电脑评论数据集,我们使用 GloVe 100维度的预训练词向量laptop review datase,这些向量在 Wikipedi 和 GigaWord 上进行了训练
5.2 Compared Methods
- Dictionary Match: 我们将其直接应用于测试集,以获得与字典中的表面名称完全相同的实体提及,通过多数投票分配类型,通过与之比较,我们可以检查神经模型相对于远程监督本身的改进
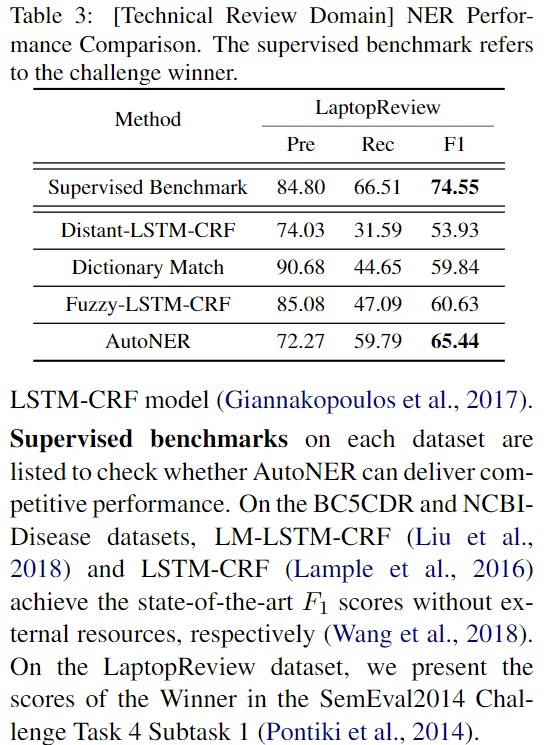
- SwellShark: 在生物医学领域,可以说是最佳的远程监督模型,尤其是在 BC5CDR 和 NCBI-Disease 数据集上(Fries等人,2017)。它不需要人工注释的数据,但是,它需要额外的 expert effort 来进行 entity span detection,包括构建POS标签,设计有效的正则表达式以及针对特殊情况进行手动调整
- Distant-LSTM-CRF: 在没有注释的训练数据的情况下,使用远程监督 LSTM-CRF model ,在 LaptopReview 数据集上获得了最佳性能
- Supervised benchmarks:
5.4 Distant Supervision Explorations
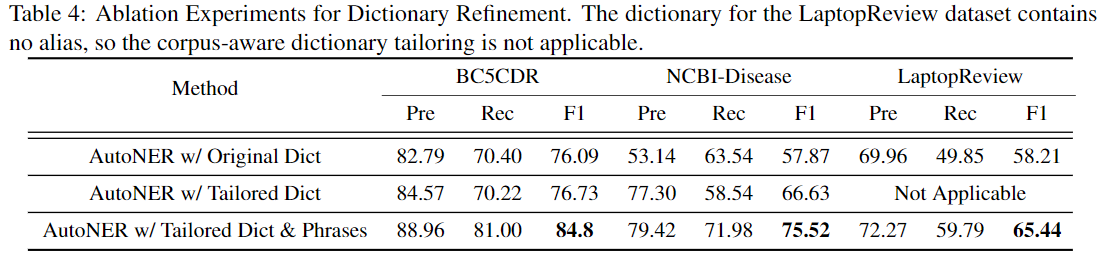
消融实验
我们研究了我们在本节中提出的两种技术的有效性。通过消融实验。如表4所示,使用定制词典总是比使用原始词典获得更好的F1分数。通过使用量身定制的词典,AutoNER模型的精度将更高,而召回率将保持不变。例如,在NCBI-Disease数据集上,它可以将召回损失从63.54%从53.14%大幅提高到77.30%%to58.54%。此外,在字典中合并未知类型的高质量短语会显着提高AutoNER模型的每个分数,尤其是召回率。这些结果完全符合我们的预期
5.5 TestF1Scores vs. Size of Raw Corpus
此外,当我们有不同大小的远程监督文本时,我们探索了 test F1 scores 的变化。我们从给定的原始语料中均匀地抽取句子样本,然后评估在所选句子上训练的 AutoNER 模型。
我们还研究了提供黄金训练集时将发生的情况。曲线可在图3中找到。X轴是distantly supervised training sentences 的数量,Y轴是测试集上的F1分数。
仅使用远程监督时,一开始就可以观察到testF1分数的显着增长趋势,但是后来,随着越来越多的原始文本,增长率降低了。
当 gold training set is available,,远程监督仍然对AutoNER有所帮助。从一开始,AutoNER的性能就不如监督基准测试。后来,在有足够 distantly supervised sentences,AutoNER 的表现优于监督基准。我们认为有两个可能的原因:(1)对那些可匹配的实体提及,远程监管更重视。(2)黄金注释可能会错过一些不错但可匹配的实体提及。这些可以指导AutoNER训练到更通用的模型,并因此具有更高的testF1分数。