『Neural Aspect and Opinion Term Extraction with Mined Rules as Weak Supervision』阅读笔记
opinion term 和其描述的 aspect 以及 sentiment 高度相关。如果在抽取出 aspect 及预测出sentiment 同时,能给出表明该 sentiment 的 opinion term,将会使结果更加完整:aspect 给出了带有情感的评论目标,sentiment 给出了对目标的情感极性,opinion term 给出了情感的原因,这三者依次回答了What(对于什么),How(情感怎么样)以及 Why(为什么是这个情感)三个问题,对于评论目标构成更全面的分析
- 提出了一种基于BiLSTM-CRF(双向LSTM条件随机场)的神经模型,用于aspect and opinion term extraction,训练数据使用人类注释数据作为基本事实ground truth 监督和用mined规则注释的数据作为弱监督进行训练,类似半监督,但是这个方法在利用未标记的数据时引入了学习到的领域知识,所以和远程监督利用外部KB也有关。
- 自动挖掘的规则特点:
- 作者说是不超过三个单词的规则,否则相关实例稀疏且对召回率的提高不大
- 其中一类基本类似关系挖掘得到的三元组,关系是 依存关系中的
- 另一类 是一对三元组,含义是 挖掘类似”联想”关系的一对,相同的 opinion term。
- 在挖掘 aspect term时,需要事先准备 predefined opinion word vocabulary;文章认为 当提取 aspect term时,关注 动词和名词;当提取 opinion时 考虑adjectives, nouns and verbs,还要建立一个 opinion word vocabulary
- 具体实现中还采取不少提高效率的方法。
code
专有名词
Abstract
我们首先提出一种算法,该算法基于依存分析结果dependency parsing results从现有的训练示例中自动挖掘提取规则 mine extraction rules。然后将挖掘的规则应用于标记大量辅助数据。最后,我们研究既可以从规则自动标记的数据中学习,也可以从人为准确注释的少量数据中学习的模型的训练过程,以训练这样的神经模型。实验结果表明,尽管挖掘的规则由于灵活性有限而不能很好地发挥作用,但是人类注释数据和带有规则标记的辅助数据的组合可以改善神经模型。
1 Introduction
产品评论中有两种类型的字词或词组(或服务,餐厅等评论,为方便起见,我们在本文中使用“产品评论”)对于意见挖掘opinion mining尤其重要:描述产品属性或属性的词或短语;以及与评论者对产品或产品方面有关的观点的看法。前者称为方面术语aspect terms,后者称为见解术语 opinion terms。例如,在“笔记本电脑的速度speed令人难以置信incredible”这句话中,“speed”是一个方面的术语,“incredible”是一个见解的术语。方面和观点术语提取的任务是从产品评论中提取上述两种类型的术语。
基于规则的方法Rule based approaches (Qiu et al., 2011; Liuet al., 2016) 和基于学习learning based 的方法 (Jakoband Gurevych, 2010; Wang et al., 2016)是完成此任务的两种主要方法。基于规则的方法通常使用基于dependency parsing结果的手动设计的规则来提取术语。这些方法的优点在于,可以始终提取在句子中使用某些特定模式的 aspect or opinion terms。
基于学习的方法将aspect or opinion terms提取 建模 为序列标记问题sequence labeling problem。尽管它们能够获得更好的性能,但它们还存在必须使用大量标记数据来训练此类模型以发挥其全部潜力的问题,尤其是在没有手动设计输入功能时。否则,它们甚至可能在非常简单的测试用例中失败(例如,请参阅第4.5节)
为了解决上述问题,我们首先使用基于规则的方法从辅助产品评论集中提取aspect and opinion term ,这可以视为不正确的注释 (use a rule based approach to extract aspect and opinion terms from an auxiliary set of product reviews, which can be considered as inaccurate annotation)。这些规则是根据dependency parsing 结果 从标记的数据中自动提取的。我们提出了一种基于BiLSTM-CRF(双向LSTM条件随机场)的神经模型,用于aspect and opinion term extraction。神经模型使用人类注释数据作为基本事实ground truth 监督和用mined规则注释的数据作为弱监督进行训练。我们将方法命名为RINANTE(Rule Incorporated Neural Aspect和Opinion Term Extraction)
我们对三个 SemEval 数据集 进行实验,这些数据集在现有aspect and opinion term extraction研究中经常使用。
- 对 基于BiLSTM-CRF的神经模型的训练 不仅包含人工标记的数据,还包含规则自动标记的数据
- 用于 aspect and opinion term extraction 任务的数据标记规则 从based on dependency parsing and POS tagging results 自动找
- 充分的对比实验
2 Related Work
方法主要有三种:基于规则的方法,基于主题建模的方法topic modeling based approaches和基于学习的方法
rule based approach:
- based on dependency parsing results (Zhuang et al., 2006; Qiuet al., 2011): 这些方法中的规则通常只涉及一个句子中最多三个单词(邱等,2011),这限制了其灵活性(但在后后面又对点做出了解释,在我们的规则挖掘算法中,我们只挖掘不超过三个单词的规则)。手工设计规则也是一项劳动密集型的工作。刘等。(2015b)提出了一种从一组预先设计的规则中选择一些规则的算法,使得所选择的规则子集能够更准确地进行抽取。然而,与我们所使用的规则挖掘算法不同,它无法自动发现规则。
- Topic modeling approaches 主题 模型(Lin and He, 2009;Brody and Elhadad, 2010; Mukherjee and Liu,2012) :能得到 粗粒度的 aspects( food,ambiance,service for restaurants, and provide related words )(将主题作为隐变量,但不能具体extract 出exact aspect terms )
- Learning based approaches by labeling each word in a sentence with BIO (Begin, Inside, Outside) tagging scheme(Ratinov and Roth, 2009)—(序列标记问题sequence labeling problem):用 CNN 或 BiLSTM 提取句子中每个word的特征,再用CRF获得更好的序列标记结果。Word embeddings 是常用的功能,也可以将手工制作的特征例如 POS tag classes 和 chunk information 组合起来以产生更好的性能(Liu等人,2015a; Yin等人,2016)。例如,Wang et al(2016)基于一个以Word embeddings为输入的句子的依存解析树 dependency parsing tree of a sentence 构造了一个recursive neural network。然后将神经网络的输出输入到CRF。XU等(2018)使用CNN模型 提取aspect terms。他们发现同时使用general-purpose and domain-specific word embeddings 可以提高性能
我们的方法利用未标记的额外数据来改善模型的性能,这与半监督学习和迁移学习有关。一些方法允许在序列标记中使用未标记的数据 Jiaoet al. (2006) propose semi-supervised CRF, Zhanget al. (2017) propose neural CRF autoencoder。与我们的方法不同,这些方法在使用未标记的数据时不会整合有关任务的知识。杨等(2017)提出了三种不同的转移学习架构,它们允许神经序列标记模型 learn from both the target task and a different but related task。文章中的模型utilizing the output of a rule based approach for the same problem ,与上面的工作区别。
我们的方法还与 weakly labeled data (Craven and Kumlien, 1999), 与信息抽取中使用的远程监管方法类似(Mintz等,2009)。
3 RINANTE
在本节中,我们详细介绍我们的方法 RINANTE。假设我们有一个带有人类注释的数据集 $D_l$ 和 一个辅助数据集$D_a$ $D_l$ 包含一组产品评论,每个评论中都带有所有方面和观点术语; $D_a$ 只包含一组未标记的产品评论。在$D_l$ and $D_a$ 中,所有评价都针对相同类型或几种相似类型的产品。通常, $D_a$ 未标记的大小比 $D_1$ 大得多。然后,RINANTE包括以下步骤
- 在 $D_l$ 用 a rule mining algorithm 挖掘 a set of aspect extraction rules $R_a$ 和 opinion extraction rules $R_o$ .
- 用 rules $R_a$ 和 $R_o$ 在 $D_a$ 的所有 reviews 中 提取 terms 作为 标签,则 $D_a$ 能被看成是 weakly labeled dataset
- 用
 训练神经网络
训练神经网络
3.1 Rule Mining Algorithm
rules 主要基于dependency relations between words 因为它们的有效性已经通过现有的基于规则的方法得到了验证(Zhuang et al., 2006; Qiu et al., 2011)
用三元组 $(rel, w_g,w_d)$ 表示依存关系,$w_g$ 是 governor支配词 $w_d$ 是 dependent从属词
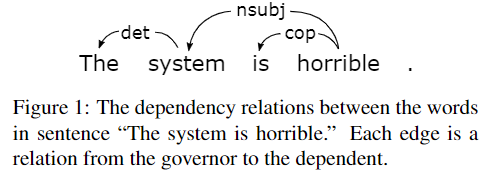
上图例子中:“system” is an aspect term, and “horrible” is an opinion term
常用的提取 aspect term 的规则:$(nsubj, O, noun^∗),$ we use $O$ to represent a pattern that matches any word that belongs to a predefined opinion word vocabulary; $noun^∗$ matches any noun word and the ∗ means that the matched word is output as the aspect word. 根据这个规则,如果 horrible 被 $O$ match到,则可以输出 aspect term “system”
细节: 在我们的规则挖掘算法中,我们只挖掘不超过三个单词的规则,因为涉及很多单词的规则可能对召回recall的影响很小,但是挖掘起来在计算上却很昂贵,并且这种模式不经常发生所以需要尽多的标记数据来cover这种情况
提取 aspect 和 提取 opinion 的算法相似
算法包含两部分
- Generating rule candidates based on a training set
- Filtering the rule candidates based on their effectiveness on a validation set


函数 RelatedS1Deps: returns a list of dependency relations. 每个dependency relations里的governor or the dependent必须是 $s_i.aspect_terms$中的一个元素
PatternsFromS1Deps: 从上面返回的list中 得到 aspect term extraction patterns

通过 POS得到 词性标注 (JJ - Adjective 形容词),通过 $ps()$ 函数从POS tag得到 the word type。只有当 $ps(w)$ 是 $noun$ or $verb$ 才自动生成上述的 pattern 或者 $w_g$ 在 predefined aspect term中时,生成关于 Opinion 的pattern是相似的。
RelatedS2Deps: 返回 a list that contains pairs of dependency relations 这个pair中的一个依存关系是RelatedS1Deps得到的,RelatedS2Deps的作用相当于为RelatedS1Deps生成的依存关系找到满足must have one word in common 的另一个依存关系。

FrequentPatterns: obtains the rule candidates。 用阈值$ T$ (T is a predefined parameter that can be determined based on the total number of sentences in S.) 划分出出现次数多的pattern
RC1和RC2分别包含基于单个依赖关系和依赖关系对的候选抽取模式。将它们合并以获得最终规则候选者列表
通过在验证集上extract aspect terms 实验,用这个结果对 mined 到的 rule 的precision进行估计,用阈值 $p$ 去掉准确率低的 rules。

显示了从包含一个依赖关系的规则模式 $r$ 来 从句子$s$中 extracting aspect terms from a sentence的算法。
函数 TermFrom: tries to obtain the whole term based on this matched seed word 具体来说,当它是动词时,它仅返回单词 $w_s$。但是当$w_s$ 是名词时,它会返回由包含$w_s$的名词word的连续序列形成的名词短语。
$V_{fil}$ includes the terms extracted with the candidate rules from the training set that are always incorrect经验法则。
在实践中,我们还构建了一个词典,该词典包括在训练集中常用的aspect terms 。该字典用于通过直接匹配提取方面的术语。(泛化能力?过于拟合在训练集上?)
文章认为 当提取 aspect term时,关注 动词和名词;当提取 opinion时 考虑adjectives, nouns and verbs,还要建立一个 opinion word vocabulary
Time Complexity
3.2 Neural Model
在 $D_l$ 中 mine 出 rule后,在 weakly labeled dataset 中 obtain the aspect and opinion terms in each sentence。得到 terms 后,标注为 BIO tag sequences(命名实体复用序列标注)
由于挖掘的规则不准确,因此结果中可能存在冲突,即,可能会提取单词同时作为aspect term and an opinion term,所以对$D_a$ 中所有的 review,都保留aspect terms 和 opinion terms 两条 tag sequences。
目标是网络模型应该能够从上述两个标签序列和一组手动标记的数据中同时学习,则表示为$t_a t_o t_m$ 分别是predicting the terms extracted by the aspect term extraction rules ……
手动准确标记的数据中的 reviews 只需一个 tag sequence。然后我们可以训练一个既有ground truth supervision又有weak supervision的神经网络模型。我们提出了两个基于BiLSTM-CRF(Huang et al。,2015)的模型,可以基于这三个任务对其进行训练。其结构如图2所示。
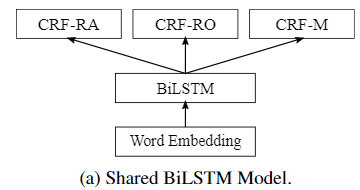
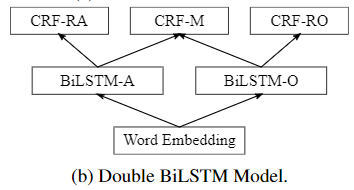
use pre-trained embeddings of the words in a sentence as input, then a BiLSTM-CRF structure is used to predict the labels of each word.

训练过程:
- 交替训练三个任务 $t_a t_o t_m$
- 预先训练 $t_a$ and $t_o$ ,然后再训练 $t_m$ 。
在第一种方法中,在每次迭代中,三个任务中的每一个都用于更新一次模型参数。
在第二种方法中,首先模型对任务 $t_a t_o$ 进行预训练,这两个任务交替训练结束后。然后将训练好保留参数的模型用来训练 $t_m$
引入早停正则化方法,对第一种方法或使用第二种方法训练 $t_m$ 时,根据验证集的性能( aspect term extraction and opinion term extraction的F1分数之和)执行。 对第二种方法 与训练时,早停是根据 the sum of theF1scores of $t_a$ and $t_o$.
在 BiLSTM layers and the word embedding layers 后 加入 dropout layers
4 Experiments
4.1 Datasets
用三个数据集:SemEval-2014 Restaurants, SemEval-2014 Laptops, and SemEval-2015 Restaurants
由于 SemEval 中使用的原始数据集在每个句子中都没有 annotation of the opinion terms,因此我们使用(Wang et al., 2016) and (Wang et al., 2017) 提供的 opinion term annotations。作为 $D_l$
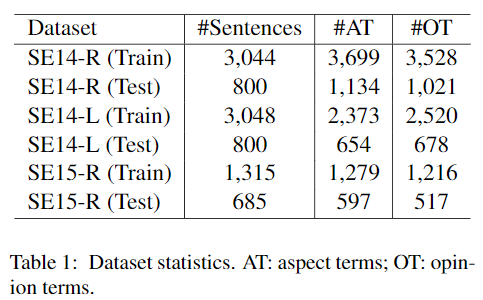
除了上述数据集,我们还使用了 Yelp dataset and an Amazon Electronics dataset (Heand McAuley, 2016) as auxiliary data to be annotated with the mined rules. 作为 $D_a$,它们还用于训练 word embeddings。
Yelp dataset 作为 SE14-R and SE15-R. 的 auxiliary data——includes 4,153,150 reviews that are for 144,072different businesses.
Amazon Electronics dataset 作为 laptop dataset SE14-L 的 auxiliary data——1,689,188 reviews for 63,001 products such as lap-tops, TV, cell phones, etc.
4.2 Experimental Setting
对于每个SemEval数据集,我们拆分训练集,并使用20%作为验证集。
对于SE14-L,我们将挖掘的规则应用于Amazon数据集的所有笔记本电脑评论,以获得自动注释的辅助数据,其中包括156,014条评论句子。
对于SE14-R和SE15-R,我们从Yelp数据集中随机抽取4%的 restaurant review 句子以应用挖掘的规则,其中包括913,443个sentences。
对于这两个自动注释的数据集,使用2,000个评论语句形成一个验证集,其余的用来形成训练集。它们在训练RINANTE的神经模型时使用。
我们使用 Stanford CoreNLP (Manninget al., 2014) 执行 dependency parsing and POS tagging。对于所有三个数据集,规则挖掘算法的规则候选生成部分中的频率阈值整数 T 均设置为10;精度阈值 p 设置为0.6。
我们将opinion word vocabulary used in (Hu andLiu, 2004) 用于aspect term extraction rules。
在Yelp数据集和Amazon数据集的所有 reviews 上分别使用 word2vec(Mikolov等人,2013)训练两组100维word embeddings。BiLSTMs 的隐藏层大小 are all set to 100. Dropout rate is set to 0.5 for the neural models.
4.3 Performance Comparison





NCRF-AE(Zhang et al., 2017): it is a neural autoencoder model that uses CRF. It is able to perform semi-supervised learning for sequence labeling. The Amazon laptop reviews and the Yelp restaurant reviews are also used as unlabeled data for this approach。
HAST (Li et al., 2018): It proposes to use Truncated History-Attention and Selective Transformation Network to improve aspect extraction
- DE-CNN (Xu et al., 2018): DE-CNN feeds both general-purpose embeddings and domain-specific embeddings to a Convolutional Neural Network model.
我们还比较了RINANTE的两个简化版本:直接使用挖掘的规则提取术语;仅使用人类注释数据来训练相应的神经模型。具体来说,第二个简化版本使用BiLSTM-CRF结构模型,将每个单词在句子中的 embeddings 作为输入。 This structure is also studied in (Liu et al., 2015a). We name this approach RINANTE (no rule) 即这个用于序列标注的结构是研究过的,用 weekly labeled data来增强了数据,在如何weekly label 上引入了自动 mine rule。
从结果可以看出,只使用挖掘规则表现不佳。但是,通过从这些规则自动标记的数据中学习,RINANTE的所有四个版本都比RINANTE(无规则)具有更好的性能。这证明我们确实可以使用这些规则的结果来改善神经模型的性能。而且,对RINANTE(无规则)的改进在SE14-L 和 SE15-R上更加明显。我们认为这是因为SE14-L相对是困难得多的数据,而SE15-R的 人工标签数据要少得多。
在四个版本的RINANTE中,RINANTE-Double-Pre在SE14-L和SE15-R上表现最佳,而RINANTE-Shared-Alt在SE14-R上则稍好。因此,我们认为,为了利用 Mined rules 的结果,与共享的 单独一层 BiLSTM 相比,使用两个分离的 BiLSTM 层作为 aspect terms and opinion terms 更为稳定。同样,对于这两个模型,我们介绍的两种训练方法都可能获得良好的性能。一般而言,RINANTE-Double-Pre的性能更稳定。
与Double Propagation的 eight manually designed rules 相比 我们的算法能够挖掘数百个有效规则。
由性能没超过的方法
与其他方法相比,RI-NANTE(不包括RINANTE-Double-Pre†)仅在SE14-L和SE15-R的方面术语提取部分上无法提供最佳性能。在SE14-L,DE-CNN表现更好。但是,我们的方法同时提取了 aspect terms and opinion term,而DE-CNN和HAST仅关注 aspect terms。在SE15-R上,方面术语提取的最佳性能系统是Elixa,它依赖于手工制作的功能
4.4 Mined Rule Results
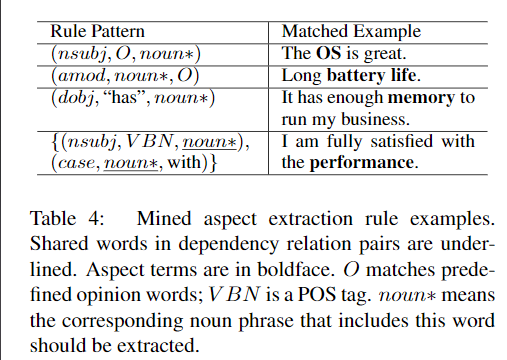
我们的规则挖掘算法提取的规则数量以及它们在测试集上提取的aspect and opinion terms。使用Intel i7-7700HQ在计算机上的每个数据集上挖掘这些规则所需的时间不到10秒2.8GHz CPU。在SE15-R上挖掘最少的规则,因为此数据集包含最少的训练样本。这还会导致挖掘的规则在此数据集上的性能较差。我们还显示了从SE14-L中提取的一些example aspect extraction rule,以及它们可以匹配并从中提取术语的例句。只需看一下模式,就很容易猜出第一,第二和第三条规则的“意图”。实际上,第一条规则和第二条规则通常用于基于规则的方面术语提取方法中(Zhuang等,2006; Qiu等,2011)。但是,我们仔细检查了所有的碎屑规则,发现它们实际上就像表4中的第四条规则,很难通过检查数据来手动设计。这也显示了人类设计此类规则的局限性。
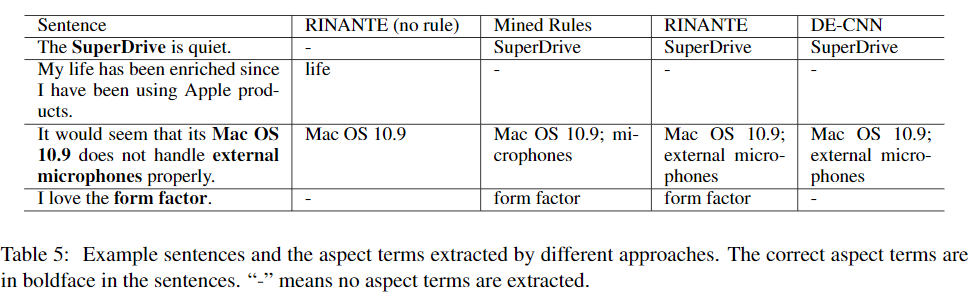
4.5 Case Study
为了帮助您了解我们的方法是如何工作的,并获得了一些关于如何进一步改进它的见解,我们在表5中显示了SE14-L的一些示例语句,并附带了RINANTE(无规则)提取的方面条款,约束规则,RINANTE(RINANTE-Double-Pre)和DE-CNN。在第一行中,可以通过基于规则的方法轻松提取方面术语“ SuperDrive”。但是,如果没有足够的培训数据,那么RINANTE(无规则)仍然无法识别它。在第二行中,我们看到这些规则还可以帮助避免提取错误的术语。第三行也很有趣:虽然挖掘的规则仅提取“microphones”,但RI-NANTE仍然能够获得正确的短语“external microphones“,而不是盲目地遵循挖掘的规则。最后一行中的句子还具有一个方面术语,可以很容易地用规则将其提取出来。RINANTE的结果也是正确的。但是RINANTE(无规则)和DE-CNN都无法提取它。