『Harnessing Deep Neural Networks with Logic Rules』阅读笔记
Logic Rules for Sentiment Classification——code
- 将 一阶逻辑 rules 表示的 知识通过 正则化(后验正则化)的方式加入NN模型参数的更新中
- 相较于 知识蒸馏时 ,论文中teacher 和student network是同时训练的
- teacher network 在每一次迭代中通过根据构造的损失函数的闭式解构造,所以实际只有要强化的student network 的参数要更新
- 认为结构知识,领域知识不能自然地以特征标签形式编码。
- 仅使用少量(一个或两个)非常直观的规则
- 测试时可以使用最后的student network p或者teacher network q,一般来讲q的表现会优于p。q更适用逻辑规则覆盖了大量样本的情况,而p更适用于规则评价复杂或者未知的情况。
- teacher-student network 这种常常是 separate training 的方式,变成了 iterative 联合训练
- teacher network 将 逻辑知识蒸馏 到student network,即可以增强各种类型的神经网络
专有名词
knowledge distillation: 知乎1, 知乎2, paper reading list
后验正则化(posterior regularization)方法
K-way classification,
K-dimensional probability simplex
groundings of a rule: a grounding is the logic expression with all variables being instantiated 即 一阶逻辑表达式中所有 变量 都实例化为具体
max-over-time 池化层,NLP中的CNN: 参考1cnblog Pooling vs Pooling-over-time
Bidirectional LSTM-CNN (BLSTM-CNN) Training System_Training_System)
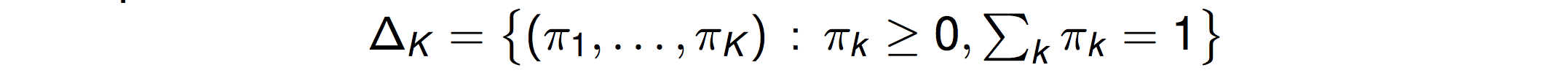
Abstract
需要将深层神经网络与结构化逻辑规则结合起来,以充分利用灵活性并减少神经模型的不可解释性。我们提出了一个通用框架,该框架可以使用声明性一阶逻辑规则增强各种类型的神经网络(例如CNN和RNN)。具体来说,我们开发了一种迭代蒸馏方法,将逻辑规则的结构化信息转移到神经网络的权重中。我们将该框架部署在CNN上进行情感分析,并在RNN上进行命名实体识别。通过一些高度直观的规则,我们获得了实质性的改进
1 Introduction
深度神经网络为从海量数据中学习模式,在图像分类,语音识别,机器翻译。玩战略棋盘游戏等,尽管取得了令人瞩目的进步,但广泛使用的DNN方法仍然存在局限性。较高的预测准确性很大程度上取决于大量的标记数据。而且纯粹由数据驱动的学习会导致无法解释的结果,有时甚至导致反直觉的结果*(Anh Nguyen等人在CVPR2015上首次提出Fooling Examples的论文 Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images)。在没有昂贵的直接监督或临时初始化的情况下,很难编码人类的意图以指导模型捕获所需的模式。另一方面,人类的认知过程表明人们不仅从具体的例子中学习(DNN确实如此),但也来自不同形式的一般知识和丰富经验。*逻辑规则提供了灵活的声明性语言,用于传达高级认知和表达结构化知识。因此,需要将逻辑规则集成到DNN中,以将人的意图和领域知识转移到神经模型中,并调节学习过程。
在本文中,我们提出了一个框架,该框架能够利用逻辑规则知识在各种任务上增强神经网络的通用类型,例如卷积网络(CNN)和递归网络(RNN)。在不同情况下,已经考虑过将符号表示 symbolic representations 与神经方法相结合。
神经符号系统根据给定规则集构建网络以执行推理 execute reasoning。为了利用通用神经体系结构中的先验知识,最近的工作使用有用的特征扩充了每个原始数据实例( augments each raw data instance with useful feature),但是网络训练仍然仅限于实例标签监督,并且遭受与上述相同的问题。此外,各种各样的结构知识不能自然地以特征标签的形式编码。
我们的框架使神经网络能够learn simultaneously from labeled instances as well as logic rules, through an iterative rule knowledge distillation (teacher-student network 知识蒸馏) procedure that transfers the structured information encoded in the logic rules into the network parameters。由于通用逻辑规则是对特定数据标签的补充,这种结合的一个自然“副产品”是对可以对半监督学习形成支持,因为使用未标记的数据可以更好地吸收逻辑知识( natural “side-product”of the integration is the support for semi-supervised learning where unlabeled data is used to better absorb the logical knowledge.)。从方法上讲,我们的方法可以看作是知识蒸馏和后验正则化(PR)方法的结合。特别是,在每次迭代中,我们都采用 posterior constraint principle from PR to construct a rule-regularized teacher,并训练感兴趣的 student network 来模仿 teacher network 的预测。我们利用软逻辑 soft logic 来支持灵活的规则编码 flexible rule encoding 。
我们将框架同时应用于CNN和RNN,并分别部署在情感分析sentiment analysi(SA)和命名实体识别named entity recognition(NER)的任务上。仅使用少量(一个或两个)非常直观的规则,both the distilled networks and the joint teacher networks strongly improve over their basic forms (without rules)。
2 Related Work
逻辑规则和神经网络的结合已经在不同的背景下被考虑过,神经符号系统Neural-symbolic system,例如KBANN和CILP ++,从给定规则 构造网络架构 来进行推理和知识获取。诸如马尔可夫逻辑网络之类的相关研究从规则集中获得了概率图形模型(而不是神经网络)。
随着深度神经网络在众多应用领域中的最新成功,将结构化逻辑知识纳入一般类型的网络以充分利用灵活性并减少神经模型的不可解释性。最近的工作是在领域知识带来的额外特征上进行训练(虽然产生了改进的结果,但并没有超出 data-label paradigm 。Kulkarni等使用专门的training procedure,对训练实例进行仔细排序,以获得图像网络的可解释神经层。Karaletsos等通过数据标签和 similarity knowledge expressed in triplet format 共同开发了一个生成模型,以学习改进的disentangled representations。
尽管确实存在允许对 潜在变量模型进行各种结构化约束编码的通用框架( allow encoding various structured constraints on latent variable model)(Ganchev等Posterior Regularization for Structured Latent Variable Models),但它们要么不能直接应用于NN网络,要么可以根据我们的经验研究,产品的性能较差。梁等以流水线的方式将预训练的结构化模型的预测能力转移到非结构化模型 ( Liang et al. (2008) transfers predictive power of pre-trained structured models to unstructured ones in a pipelined fashion.)。
我们提出的方法的不同之处在于,我们使用迭代规则提炼过程(use an iterative rule distillation process)将声明性一阶逻辑语言表示的丰富结构化知识有效地转移到参数中通用神经网络我们表明(effectively transfer rich structured knowledge, expressed in the declarative first-order logic language, into parameters of general neural networks)
3 Method
在本节中,我们介绍将逻辑结构化知识封装到神经网络中的框架。这是通过迫使网络 emulate the predictions of a rule-regularized teacher,并在整个培训过程中迭代地发展两个模型来实现的 evolving both models iteratively throughout training(第3.2节)。该过程与网络体系结构无关,因此适用于一般类型的神经模型,包括CNN和RNN。我们通过 posterior regularization principle 后验正则化作为 logical constraint setting 构建 teacher network。提供了闭式解
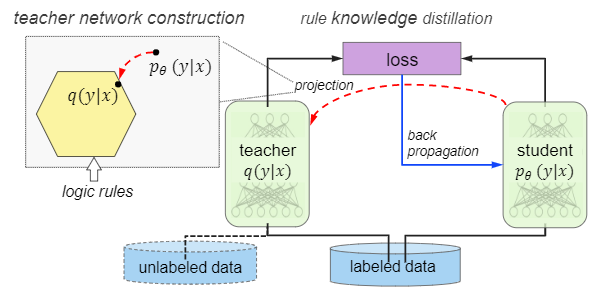
左上是简略图表示 teacher network 的构建过程:obtained by projecting the student network to a rule-regularized subspace (red dashed arrow)
student network 的 训练过程: balance between emulating the teacher’s output (black solid arrows)知识蒸馏过程 和 predicting the true labels (blue solid arrows)
3.1 Learning Resources: Instances and Rules
我们的方法允许神经网络从特定的示例和一般规则中学习。在这里,我们给出了这些“learning resources”的设置

输入变量 $x$, 目标变量 $y\in\{0,1\}^K$ 是 class label 的 one-hot 编码,但是,我们的方法规范可以直接应用于其他情况,例如回归和序列学习(例如NER标签,它是分类决策的序列)。

first-order logic (FOL) rules $R_l$ 定义在输入目标空间 $(\mathcal{X,Y})$ 规则集合的第 $l$ 条规则,with confidences 权重 $\lambda_l \in[0,\infty]$ ,当 $\lambda_l =\infty$ 表示这是一条 hard rule,则 all groundings are required to be true (=1).
举例:
训练集 $\mathcal{D}=\{(x_n,y_n\}_{n=1}^N$ 是 $(x,y)$ 的一组实例化集合
取一个minibatch $(X,Y)\subset(\mathcal{X,Y})$ ?为什么是样本空间的子集而不是 训练集 $\mathcal{D}$
groundings 为 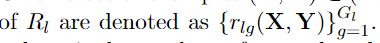
实际情况下,a rule grounding 只能 cover a single or subset of examples,即使我们给出的公式是在整个集合上的最通用的形式
用 soft logic 进行编码,for flexible encoding and stable optimization
松弛后的逻辑运算规则,用 Lukasiewicz t-norm co-norm 分别作为 逻辑 AND 和 OR 的松弛形式
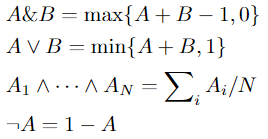
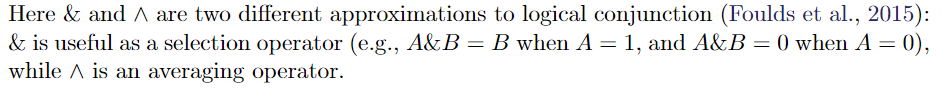
3.2 Rule Knowledge Distillation 逻辑规则的知识蒸馏

为了整合编码在 rules 中的 information,我们建议对网络进行训练,来模仿 the outputs of a rule-regularized projection of $p_{\theta}(y|x)$ ,表示为 $q(y|x)$ ,这个正则化的投影,明确包含了 rule constraints 为正则化项。每次迭代中,通过将 student network 输出 的条件概率 $p_\theta$ 投影到 受规则约束rule constraints 的子空间中来构造 $q$,因此具有has desirable properties。
$q$ 的预测行为 体现了正则化子空间 和 结构化规则 structured rules 的信息。因此student network模拟 q 的 输出用于传递 rules的知识到student network的输出分类 $p_\theta$
knowledge distillation其实就是 $p(y|x)$ ( student network) 模仿 $q(y|x)$ (Teacher network )的输出
(即soft predictions ) 的误差大小 和 预测真实 label 的误差之间的 权衡结果 去 update student network 的参数 $\Theta$

t 是训练轮次,$\ell$ 是不同任务中的损失函数 loss(如在分类问题中,l 是交叉熵)$\sigma_\theta$是预测函数 ,$s_n^{(t)}$ 是teacher network 的预测结果 即作者说的 soft predictions $q$ on $x_n$ 。 $π$是校准两个目标相对重要性的模仿参数。 与传统的知识蒸馏不同的是,our teacherand student are learned simultaneously during training。
(尽管可以通过像以前一样仅使用数据标签实例对网络进行完全训练后将其投影到规则正则化子空间,或者通过直接优化投影网络来将神经网络与规则约束相结合) 这个方法性能更好
因为 这种方式将逻辑规则形式的结构化信息引入到神经网络的权重中,不需要依靠显示的规则表达,可以将 $p_\theta$ 用于在规则评估成本高昂甚至无法使用时在测试时预测新示例 (i.e., the privileged information setting (Lopez-Paz et al., 2016)) .
且上式中的第二项对 teacher network 的学习 除带有标记的示例外,还可以使用丰富的未标记数据进行扩充,这使半监督学习可以更好地吸收规则知识
3.3 Teacher Network Construction
$q(y|x)$ 为 the outputs of a rule-regularized projection of $p_{\theta}(y|x)$ ,这个正则化的投影,明确包含了 rule constraints 为正则化项。
我们在构造 logic constraint setting 时 采用了 后验正则化 posterior regularization principle。
$\mathcal{R}=\{(R_l,\lambda_l)\}_{l=1}^L $ FOL rules 集合 包含L条 rules ,构造 $q$ 需要 1. fits the rules 2. staying close to student network 的输出 $p_\theta$
- fits the rules: 对 rules $(R_l,\lambda_l)$ ( indexed by i),和其所有在 这个 minibatch $(X,Y)$ 中的 groundsing ( indexed by g), 有 约束: $\Bbb{E}_{q(Y|X)}[r_{lg}(X,Y)]=1$ 即正则化投影后得到的 $q(y|x)$ 输出分布,(x,y) pairs 能用 rules 全覆盖,则将输出的分布 constraint 到 rule-regularized space
- staying close to student network 的输出 $p_\theta$: 用 KL 散度 计算 student network 和 teacher network 输出分布的距离
将两者结合起来,在对约束进行一定的松弛,得到下面的优化目标
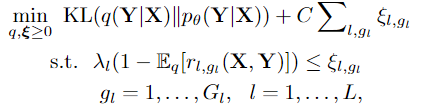
其中 $\xi_{l,gl}$ 是相应逻辑约束的松弛变量; C 是正则化常数。
该问题可以看作是将pθ投影到约束子空间中,该问题是凸的,可以通过其对偶式的闭式解有效地解决
q 的 共轭式 的 闭式解: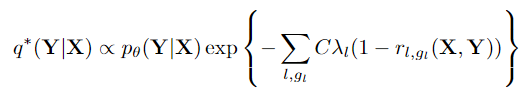
具有较大λ1的强规则将导致无法满足约束条件的预测概率较低
我们的框架与后验正则化(PR)方法有关(Ganchev et al。,2010),该方法在无监督的情况下对模型后验放置约束(places constraints over model posterior in unsupervised setting)。
在分类任务中,我们的优化程序类似于 对 PR的改进EM算法,通过使用式 中的交叉熵损失并在 与 标记数据的样本集 $D$ 不同的未标记数据集上 评估第二个损失项,从而使等式对应于 E-estimation步骤 ,等式类似于M-maximizes步骤。这从另一个角度阐明了为什么我们的框架会起作用。但是,我们在实验(第5节)中发现,要产生强大的性能,在等式(2)的两个损失项中使用相同的标记数据 $x_n$ 至关重要,以便在模拟软预测与预测正确的硬标记之间形成直接的折衷
中的交叉熵损失并在 与 标记数据的样本集 $D$ 不同的未标记数据集上 评估第二个损失项,从而使等式对应于 E-estimation步骤 ,等式类似于M-maximizes步骤。这从另一个角度阐明了为什么我们的框架会起作用。但是,我们在实验(第5节)中发现,要产生强大的性能,在等式(2)的两个损失项中使用相同的标记数据 $x_n$ 至关重要,以便在模拟软预测与预测正确的硬标记之间形成直接的折衷
3.4 Implementations.
Algorithm 1中总结了我们框架的迭代蒸馏优化过程。
训练过程中,在每次迭代都要计算 the soft predictions of $q$,如果等式中的 rule constraint 以和 基本神经模型 pθ(例如,第4.1节中的情感分类中的 “but“ rule)相同的方式 分解factored ,则可以通过枚举直接进行计算。如果约束引入了额外的依赖关系,例如,二元语法依赖关系 作为NER任务中的转换规则(第4.2节),我们可以使用动态编程进行有效的计算。对于高阶约束(例如NER中的列表规则 listing rule),我们通过 Gibbs采样 进行近似,该采样针对每个位置 $i$ 反复从$q(y_i | y_{-i},x)$进行采样。如果约束跨越多个实例,我们将相关实例组合成 minibatches 进行联合推理 joint inference(并在组太大时随机打破一些依赖关系)。请注意,计算软预测 soft predictions是高效的,因为只需要一个NN forward pass 就可以计算基本分布pθ(y | x)(如果需要,还可以计算一些基本规则的真值)。

类似于 EM 算法,初始化模型参数 $\theta_0$
p v.s. q at Test Time
在测试时,我们可以 we can use either the distilled student network $p$ ,or the teacher network $q$ after a final projection。我们的经验结果表明,两种模型在仅使用数据标签实例进行训练的基础网络上均得到了显着改善。一般而言,q 的性能优于 p。特别地,当逻辑规则引入需要联合推理的附加依赖性(例如,跨越多个示例 spanning over multiple examples)时,q 更适合。相反,如上所述,p 更加 lightweight and efficient,并且在 rule evaluation is expensive or impossible at prediction time 时很有用。我们的实验广泛地比较了 p 和 q 的性能
Imitation Strength $\pi$
balances between emulating the teacher soft predictions and predicting the true hard labels.
由于教师网络是由 pθ 构建的,因此在训练开始时会产生低质量的预测,因此我们更倾向于在初始阶段预测真实标签。随着训练的进行,我们逐渐偏向于 模仿教师的预测以有效地提取结构化知识。具体而言,我们在迭代 t≥0 时定义 $\pi^{t}=\min\{\pi_0,1-\alpha^t\}$,其中 α≤1 指定衰减速度,而 π0<1 是下限
4 Applications
我们已经介绍了我们的框架,该框架足够通用,可以使用规则来改进各种类型的神经网络,并且易于使用,因为允许用户通过声明性的一阶逻辑来 注入其知识和意图。在本节中,我们通过将其应用于两种主力网络架构(即卷积网络和递归网络)以及两种代表性应用(即句子级情感分析sentence-level sentiment analysis(这是一个分类问题)和名为实体识别 named entity recognition(序列学习问题)来说明我们方法的通用性。
实验用的网络 , we largely use the same or similar networks to previous successful neural models。
We then design the linguistically-motivated rules to be integrated 在设计rules
4.1 Sentiment Classification
句子级别的情感分析是要识别单个句子背后的情感(例如,正面或负面)。这项任务对于许多观点挖掘 opinion mining 应用至关重要。该任务的挑战之一是捕捉句子中的对比感contrastive sense(例如,通过“ but”转折词 连词 等 conjunction)
Base Network
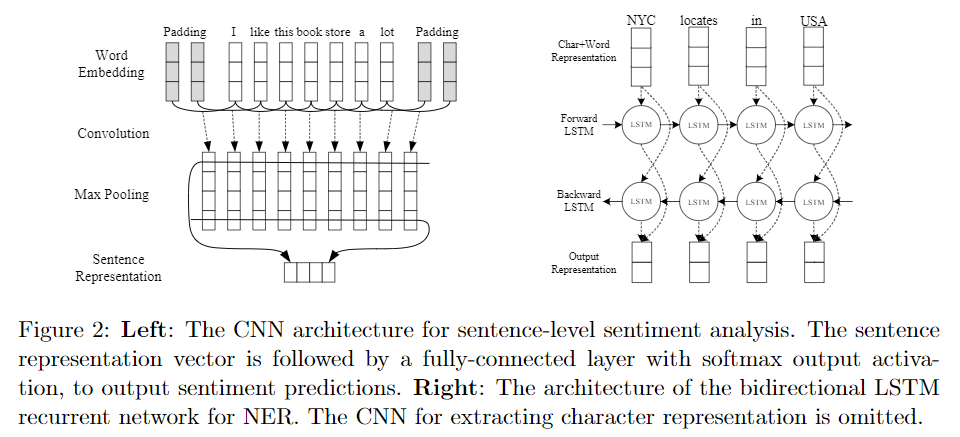
我们使用(Kim,2014)中提出的单通道卷积网络 single-channel convolutional network。该简单模型在各种情感分类基准上均具有令人信服的性能。该网络在给定句子的单词向量之上包含一个卷积层,然后是一个最大时间 max-over-time 池化层,然后是一个具有softmax输出激活的完全连接层。卷积运算是将 filter 应用于句子的一个窗口,使用具有不同窗口大小的多个 filter 来获得多个特征。图2左面板显示了网络体系结构。
Logic Rules
普通神经网络的一个困难是识别对比意义 contrastive sense,以便准确地捕捉主导情绪 dominant sentiment 。连词“ but”是句子中这种情绪变化的有力指示之一,其中“ but”之后的从句情绪通常占主导地位。因此,如果我们认为句子 $S$ 具有 $“ A-but-B” $ 结构,并期望整个句子的情感与从句B的情感一致。则一阶逻辑规应写为:
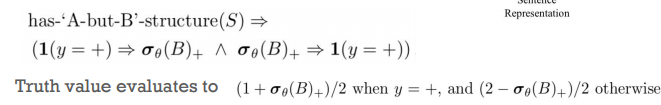
$r\equiv r_{body} \rarr r_{head} \equiv \tilde \neg r_{body}\tilde\lor r_{head}$ (条件表达式性质),
class $+$ 代表 “positive” ,$\sigma_\theta(B)_+$ 是 soft prediction vector $\sigma_\theta(B)$ 中 class ‘+’ 所对应的 element。
请注意,这里我们假设 二分类(即正面和负面),尽管为更细粒度的情感分类设计规则很简单
4.2 Named Entity Recognition
识别出句子中命名实体的 边界与类别 的任务称为 NER 类别例如“persons”和“organization”
为每个单词分配一个 命名实体 tag ,标注格式:”X-Y“ 其中 X is one of BIEOS (Beginning, Inside, End, Outside, and Singleton) and Y 是 实体类别 entity category。 有效的标签序列 valid tag sequence 必须通过标签方案 tagging scheme 的定义并 遵循某些约束。此外,在句子内或句子之间具有结构(例如,lists)的文本通常会暴露出一些一致性模式 consistency patterns
Base Network
该基础网络与(Chiu and Nichols,2015)为NER提出的 bi-directional LSTM recurrent network (called BLSTM-CNN) 具有相似的架构,其性能优于大多数先前的神经模型。 该模型使用CNN和预训练的单词向量分别捕获字符级和单词级信息。然后将这些功能输入带有LSTM单元的双向RNN中进行序列标记。(NER也可看成是 序列标记问题)与Chiu和Nichols,2015年相比,我们省略了字符类型和大写特征以及输出层中的加性转换矩阵additive transition matrix。图2右侧面板显示了网络架构
Logic Rules
base network 很大程度上在每个位置做出独立的标记决策,而忽略了有效标记序列对连续标记的约束(例如, I-ORG cannot follow B-PER 开头的人名后面不跟着机构名?)。与最近的工作(Lample等人,2016)不同,后者添加了条件随机字段(CRF)来捕获输出之间的二元语法依赖关系,相反,我们应用了不会引入额外参数来学习的逻辑规则。一个示例规则是: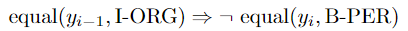 将confidence 系数设置为 $\infty$ ,防止任何的冲突。
将confidence 系数设置为 $\infty$ ,防止任何的冲突。
进一步利用同一文档的句子内部和之间的 $list$ 结构,具体而言,列表中相应位置的命名实体可能位于同一类别中。例如:in “1. Juventus, 2. Biarcelona, 3. …” we know “Barcelona” must be an organization rather than a location, since its counterpart entity “Juventus” is an organization
识别 补充材料中的 list 结构 和 counterparts 对等类别,设计 rule: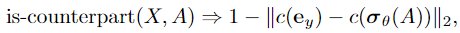
$e_y$ 是 one-hot encoding of $y$ (the class prediction of X) $c(·)$ 将具有相同类别的标签上的probability mass 折叠为单个概率,从而得出长度等于类别数量的向量. 用 $\ell_2$ 距离 作为 衡量 prediction of $X$ 和 其 对等 counterpart $A$ 的 closeness,将 距离在[0,1]间取值 即 软真值
5 Experiments
我们发现能够进行显式联合推理的教师网络 q 比 蒸馏的学生网络 p性能好
我们通过在各种公共基准 public benchmarks 上评估 情感分类和命名实体识别 的应用来验证我们的框架。
实验参数:

5.1 Sentiment Classification
commonly used benchmarks:
- SST2,斯坦福情感树库 Stanford Sentiment Treebank(Socher et al。,2013),在训练/开发/测试集中包含2个类别(负和正),分别包含6920/872/1821个句子。接下来(Kim,2014年),由于句子和短语上都提供了标签,因此我们在句子和短语上都训练了模型。
- MR(Pang and Lee,2005),一组10,662个单句电影评论,带有负面或正面情绪。
CR(Hu和Liu,2004),各种产品的客户评论,包括2个类(负面或正面) 和3,775个实例。
For MR and CR, we use 10-fold cross validationas in previous work. 在这三个数据集中,每个数据集中约有15%的句子包含“ but”一词。
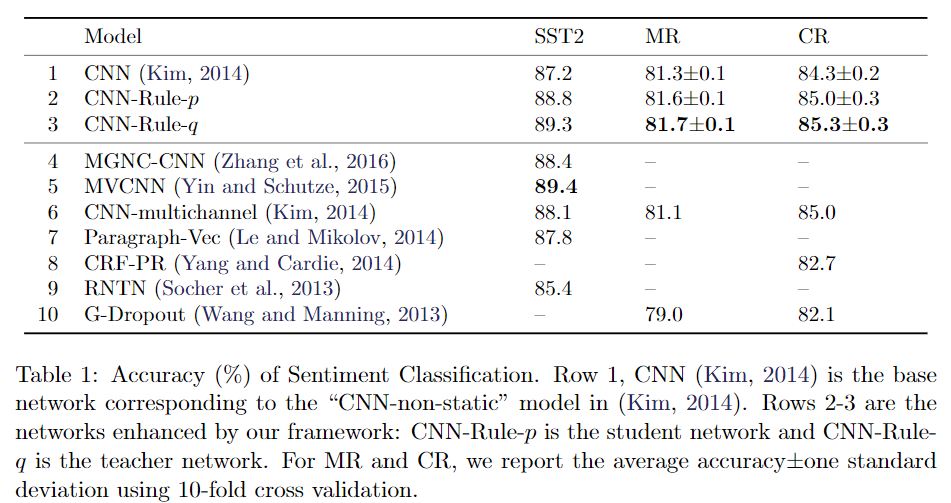
对于基础神经网络,我们使用(Kim,2014年)中的“非静态”版本,且配置完全相同。使用word2vec初始化单词向量(Mikolov等,2013),并在整个训练过程中对其进行微调,并使用SGD,Adadelta优化器训练神经参数。
第5行)是唯一显示出比我们更好的结果的系统。他们的神经网络组合了各种不同的预训练词嵌入集diverse sets of pre-trained word embeddings(而我们仅使用word2vec),并且比我们的模型包含更多的神经层和参数。
为了进一步研究我们的框架在 集成结构化规则知识这一类方法中 的有效性,我们将其与其他各种可能的集成方法进行了比较。表2列出了这些方法及其在SST2任务上的性能。
 与第6行中的流水线方法(类似于结构编译工作)(Liang等人,2008)相比,我们的迭代蒸馏(3.2节)提供了更好的性能。我们方法的另一个优点是我们只训练一组神经参数(因为 teacher network的输出 条件概率是通过闭式解得到的),而不是两个单独的参数集。
与第6行中的流水线方法(类似于结构编译工作)(Liang等人,2008)相比,我们的迭代蒸馏(3.2节)提供了更好的性能。我们方法的另一个优点是我们只训练一组神经参数(因为 teacher network的输出 条件概率是通过闭式解得到的),而不是两个单独的参数集。
与基础CNN相比,distilled 的 学生网络“ -Rule-p” 具有更高的准确性,而“ -project” 和 “ -opt-project” 则将CNN明确投影到规则约束的子空间 rule-constrained subspace 中。这验证了我们的蒸馏过程将结构化知识有效地转化为神经参数。“ -opt-project”的准确性较差的部分原因是其神经网络部分的性能较差,其仅达到85.1%的准确性,并导致对等式(5)中“ but”规则的评估不准确。
在半监督学习中的应用
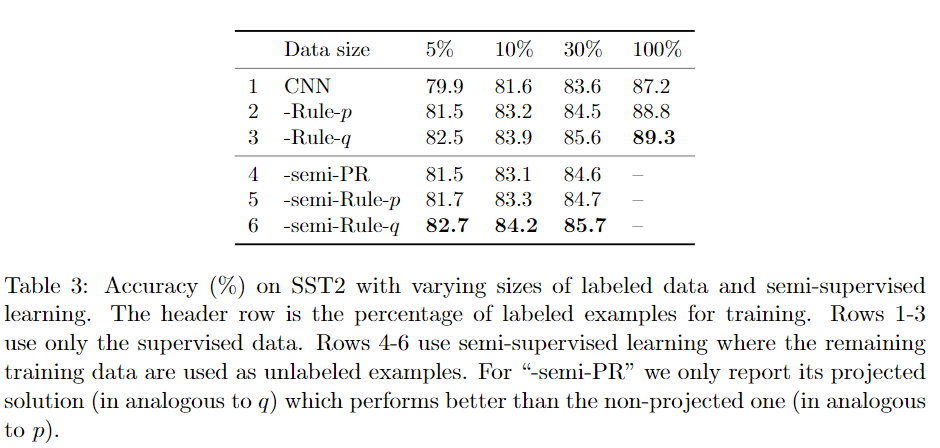
接下来,我们将探索具有不同数量的标记实例 varying numbers of labeled instances 的框架的性能,以及利用未标记数据的效果。直观地讲,我们希望使用较少标记的示例来提高通用规则对性能的贡献,而未标记的数据应有助于更好地从规则中学习。这可能是一个有用的属性,尤其是在数据稀疏且标签价格昂贵的情况下。表3示出了结果。降采样subsampling 是在句子级别上进行的。也就是说,例如,在“ 5%”中,我们首先随机均匀地选择5%的训练句子,然后根据这些词句及其短语对模型进行训练。(That is, for instance, in “5%” we firstselected 5% training sentences uniformly at random, then trained the models on these sen-tences as well as their phrases.)结果证实了我们的期望。1)第1-3行给出仅使用数据标签子集进行训练的准确性。在每种情况下,我们的方法始终优于基本的CNN。2)“ Rule-q”在5%的数据(保证金为2.6%)上的改进要比较大的数据(例如,在10%的数据上为2.3%,在30%的数据上为2.0%)更高。数据上下文。3)通过在第5-6行中添加未标记的实例进行半监督学习,可以进一步提高准确性。4)第4行,“-semi-PR”是后验正则化(Ganchev等人,2010),它施加了规则约束在训练过程中仅通过未标记的数据。我们的蒸馏框架始终提供更好的结果。
5.2 Named Entity Recognition
NER 任务:

我们 的 base BLSTM网络 使用的配置与Chiu和Nichols(2015)中的配置基本相同,不同之处在于,除了略微的体系结构差异(第4.2节)之外,我们还使用 Adadelta 进行参数更新。(Pennington et al。,2014)GloVe词向量 用于初始化词特征 word features。