『Neural Module Networks』阅读笔记
- 网络模块的基本组成,使得compositional 的 structure能覆盖大部分的问题
- 将自然语言问题 映射 到 布局 layouts,布局包括所用模块和模块间的连接关系,根据 layouts to assemble the final prediction networks。
- 自然语言问题通过依存句法分析和基本的词法处理
- 因为动态的网络结构,some weights are updated much more frequently than others. 自适应学习率算法更好,但有人指出调参能力一般
- Created SHAPES, a synthetic dataset that places such compositional phenomena at the forefront
code
专有名词
VQA: Visual question answering
modeling common sense knowledge
dataset biases
grounding the question in the image——grounding task
更普遍地是利用 集理论 set-theoretic approaches 之于 经典语义解析方法 classical semantic parsing 和 注意方法attentional approaches 之于计算机视觉 之间的自然相似性。
lexical analysis——词法分析 是计算机科学中将字符序列转换为标记(token)序列的过程
adaptive per-weight learning rates
hard perceptual problems
monolithic network
Abstract
Visual question answering 本质上是组合的,——例如 where is the dog ?与 what color is the dog? where is the cat? 这些问题都有同样的语言学的子结构 substructure 。 本文旨在同时利用深层网络的表示能力 representational capacity 和 question的 语言结构 compositional linguistic structure 。建立和学习neural module networks,该过程将联合训练 jointly-trained 的模块 组成了用于回答问题的深层网络。 我们的方法将问题分解为它们的语言子结构 linguistic substructures,并使用这些结构动态实例化 模块化的网络 dynamically instan-tiate modular networks(具有可重复使用的组件, recognizing dogs, classifying colors 等 )。由模块组合成的复合网络 are jointly trained。我们在两个具有挑战性的数据集上评估我们的方法,在 VQA natural图像数据集和有关抽象形状的复杂问题的新数据集上均获得了最新的结果
1. Introduction
NMN——neural module networks 动态地基于语言结构,将模块是组成深层网络dynamically composed into deep networks based on linguistic structure.
VQA这些问题需要计算机结合常识及视觉,语言的理解作出回答。
recent work:
- 将问题表示为词袋,或使用递归神经网络对问题进行编码[A neural-based approach to answering questions aboutimages.] 然后训练一个简单的分类器。
- 对于文本 QA[23] 和 图片 QA[27],使用语义解析器 semantic parsers 将问题分解为逻辑表达式 logical expressions 。These logical expressions are evaluated against a purely logical representation of the world, which may be provided directly or extracted from an image [21]
并不是像传统的神经网络模型一样用一个整体,我们的方法是用多个模块化网络组合一个网络模型,模块是 specialized 和 jointly-learned。 不使用逻辑表达,我们模型输出的表达 remain entirely in the domain of visual features and attentions.
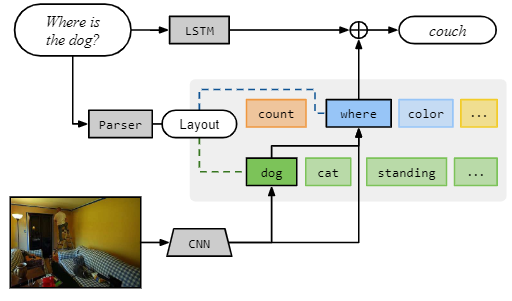
模型简要:
- 使用自然语言解析器解析每个问题,以此分析出回答问题所需要的基础组成单元(attention, classification 等)以及组成单元之间的联系。
- 以上图为例,首先产生一个对狗的attention,将其输出到位置描述器 location describer。
- 根据模型具体结构,模块间传递的这些消息可能是原始图像特征、attention或分类决策 classification decision;
- 每个模块将特定输入映射到输出类型。图中用不通的颜色表示不同的模块,用绿色表示attetion-producing模块(like dog),用蓝色表示标签模块 labeling modules (like where)。需要注意的是,所有NMN中的模块都是独立的,可组合的,这使得NMN可以对每个问题实例组合成不同的网络,在测试中出现的结构,训练过程中可能并不曾出现过,NMN也能work。
- 除NMN以外,用LSTM模块去读取question,用来学习常识性的知识。
- additional step which has been shown to be importantfor modeling common sense knowledge and dataset biases[28]
evaluation:
- VQA: VQA数据集中的许多问题都非常简单,几乎不需要 composition or reasoning。
- 一个新的合成图像数据集,其中包含涉及空间关系,集合理论推理以及形状和属性识别的复杂问题。——SHAPES——This dataset consists of complex questions about simple arrangements of colored shapes , 问题包含两个到四个属性,对象类型或关系。SHAPES数据集包含244个唯一问题,每个问题与64个不同的图像配对(总共15616个唯一问题/图像对,训练集中有14592个,测试集中有1024个)。
expension:
尽管本文考虑的所有应用程序都涉及视觉问题解答,但该体系结构更为通用,可以轻松应用于视觉参照表达解析 visual referring expression resolution[9,34]或有关自然语言文本的问题 natural language texts 解答
2. Motivations
- There is no single “best network” for full range of computer vision tasks
- 用 a prefix of a network trained for classification 作为系统的初始状态是现在的常态,大幅减少训练时间并提高准确性
因此,尽管网络结构不是通用的(就同一网络而言,它适用于所有问题),但它们至少在经验上是模块化的(就一项任务而言,中间表示对于许多其他任务都是有用的)
语言的组成性质意味着此类步骤的处理数量可能不受限制,从问题和图像到答案的回答过程看成 highly-multitask learning setting。Moreover, multiple kinds f processing might be required—repeated convolutions might identify a truck, but some kind of recurrent architecture is likely necessary to count up to arbitrary numbers.
所以构建 modular, composable, jointly-trained neural networks.
3. Related work
1. Visual Question Answering
回答有关图像的问题有时称为“视觉图灵测试”,在由配对图像,问题和答案组成的合适的数据集出现之后变得热门。
DAQUAR dataset 仅限于室内场景 indoor scenes,并且包含的示例相对较少。
COCOQA数据集 和 VQA数据集 明显更大,并且具有更多的视觉多样性 visual variety。两者都是基于来自COCO dataset 的图像。尽管 COCOQA 包含从与 COCO 数据集相关联的描述 descriptions 中自动生成的问题-答案对,但 has crowed sourced questions-answer pairs 。我们评估了VQA的方法,这是两个数据集中更大,更自然的一个。
“经典”方法包括[27,21]。这两种方法在使用 semantic parser 上类似于我们的方法,但是它们依赖于固定的逻辑推理器 logical inference ,而不是学习的合成操作 compositional operations 。
文献[33,26,10]中已经提出了几种用于 视觉询问 visual questioning 的神经模型,所有这些模型都使用标准的深层序列建模机制 deep sequence modeling machinery 来构造图像和文本的联合嵌入,并立即将其映射 a distribution over answer 。在这里,我们试图更显式地对产生每个答案所需的计算过程进行建模,但是受益于产生序列和图像嵌入的技术,这些技术在先前的工作中已经变得很重要。
视觉质询 visual questioning 的一个重要组成部分是在图像中定位问题。[18,32,17,20,14]中完成了 grounding task 这种基础任务,在此作者试图在图像中的定位短语 localize phrases in an image[39],使用注意力机制预测句子生成过程中每个单词的热图 predict a heatmap for each word during sentence generation。这些方法启发了我们模型的注意力成分。
2. General compositional semantics
在学习 如何回答 question–answer pairs 中有关结构化知识表示的问题时,有大量文献,无论有没有联合学习简单谓词的意义 meanings [23,21]。 回答问题的 task 之外,已经提出了几种用于指令跟随的模型,这些模型在底层连续控制信号上施加了离散的“planning structure” [1,30]。我们没有意识到过去使用 语义解析器 来预测网络结构,或更普遍地是利用 集理论 set-theoretic approaches 之于 经典语义解析方法 classical semantic parsing 和 注意方法attentional approaches 之于计算机视觉 之间的自然相似性。
3. Neural network architectures
为每个输入数据选择不同的网络图的想法是递归网络(其中网络随着输入长度的增长而增长)和递归神经网络(例如根据句法结构构建网络)的基础(36)。但是,这两种方法最终都涉及到单个计算模块(例如LSTM [13]或GRU [5]单元)的重复应用。从另一个方向看,某些类型的存储网络[38]可以看做是我们模型的一种特殊情况,带有固定的计算图,由一列 find modules 和 一个 describe module 组成。具有模块化子结构的其他 policy- and algorithm-learning approaches 包括[16,4]。[31]描述了一种程序,该程序用于学习从行为被完全指定的 functional primitives 集合中汇编程序的过程。
主要的贡献: 动态组装模块,同时允许节点执行不同类型的“消息”(原始图像特征,关注度和分类预测)来进行异构计算并在模块间传递“消息”
4. Neural module networks for visual QA
每个训练的数据项被想象成一个三元组$(w,x,y)$:
- $w$ is a natural-language question
- $x$ is an image
- $y$ is an answer
整个模型由一个模块集 $\{m\}$ 完全指定,相关参数为 $\theta_m$,以及 a network layout predictor $P$ ,它将字符串映射成网络。给定 $(w,x)$ ,通过 $P(w)$ 实例化一个网络。并使用 $x$(或 $w$ )作为输入,得到一个关于标签的分布( (for the VQA task, we require the output module produce an answer representation))。所以预测分布 predictive distribution 可以表示为 $p(y|w, x; \theta)$
4.1. Modules
我们的目标是确定可以组装为任务所需的所有配置的一小部分模块 modules 。这对应于识别可组合的视觉原语 composable vision primitives 的最小集合。这些模块操作三种基本数据类型:图像, unnormalized attentions 和 标签 labels。对于本文描述的特定任务和模块,几乎所有有趣的组合现象都发生在 注意力空间 the space of attentions 中,并且将我们的贡献更狭义地描述为“注意力组合”网络并非没有道理。但是,将来可能会轻松添加其他类型(用于新应用或在VQA域中具有更大的覆盖范围)
Notion: $\text{TYPEINSTANCE}$
example: $\text{}$ $\text{find[red]}$ locates red things; $\text{find[dog]}$ locates dogs
Weights may be shared at both the type and instance level
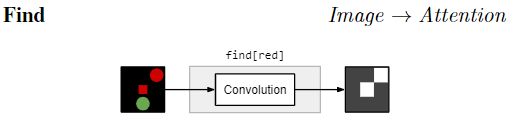
$\text{find[c]}$ :对图像卷积 with a weight vector ,不同 c 是不同的 weight vector,生成 a heatmap or unnormalized attention.
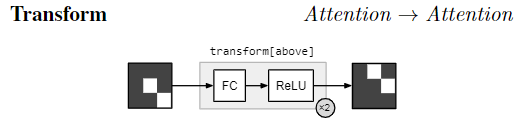
$\text{transform[c]}$ :多层感知机实现, performing a fully-connected mapping from one attention to another。不同 c 是不同的 mapping weight。作用: take an attention and shift the regions of greatest activation upward 。$\text{transform[not]}$ should move attention awayfrom the active regions 实验经验说明,第一个FC层输出向量大小为32,第二个FC输出和transform的输入维度一致
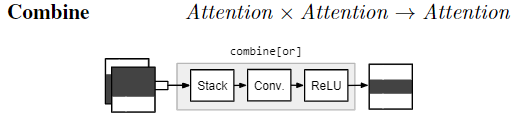
$\text{combine[c]}$ : 作用 merges two attentions into a single attention $\text{combine[and]}$ : be active only in the regions that are active in both inputs $\text{combine[or]}$ : be active where the first input isactive and the second is inactive
transform 和 combine 对应的 问题 —— 识别shape 和 color ,以及 其中的 空间上和 逻辑上的联系,需要转移 和 组合 attention
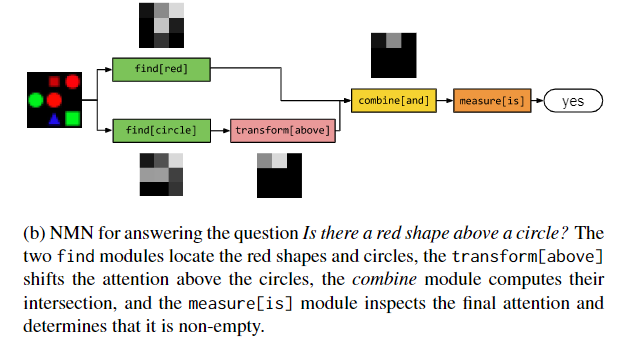
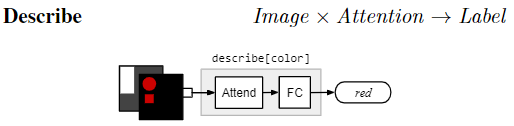
$\text{describe[c]}$ 输入:an attention and the input image 。 将两者映射到关于 label 的分布。过程: first computes an average over image features weighted by the attention; then passes this averaged feature vector through a single fully-connected layer 例如,describe [color]应该返回所关注区域中颜色的表示
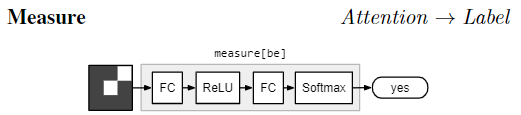
$\text{measure[c]}$ takes an attention alone and maps it to a distribution over label 由于模块之间传递的 attention 是没经过 normalization 的, 所以经过 $\text{measure}$ 模块可以 evaluating the existence of a detected object, or counting sets of objects
4.2. From strings to networks
已经建立了模块集合,就需要将它们根据不同问题组装成不同的网络布局。从自然语言问题到神经网络实例化有两个步骤。
- 我们 将自然语言问题 映射 到 布局 layouts,布局包括所用模块和模块间的连接关系;
- 根据 layouts to assemble the final prediction networks.
对自然语言问题:use standard tools pretrained on existing linguistic resources to obtain structured representations of questions
之后对这一块的修改,可以是将 question 的结构化表示预测 可以和 后面的 jointly learn
Parsing
作者使用 Stanford Parser 对每个问题进行解析,依存句法分析 表达了句子各部分之间(例如,对象及其属性或事件及其参与者之间的语法关系),并提供了一种轻量级的抽象,使其脱离了句子的表面形式。解析器还执行基本的词法处理 lemmatization,,例如将 kites 转成 kite 和 were 转成 be。这减少了模块实例的稀疏性——标准化减少空间。
接下来,我们过滤出 与问题中的 wh词疑问词 和 copula系动词 相关联的 依存关系集(遍历的确切距离 根据任务的不同 而变化 以及 $how many$ 是作为特殊情况对待 )。这给出了一个简单的符号形式来表达句子含义的(主要)部分。比如, what is standing in the field 变成了 what(stand); what color is the truck 变成了 color(truck);is there a circle next to a square 变成了is(circle, next-to(square))。
- 这些表示与组合逻辑 combinatory logic [23]有一些相似之处:每个叶节点都是隐含的以图像为输入的函数,而根表示计算的最终值。但是,尽管我们的方法是compositional and combinatorial 的,但不是 logical 的: 推论计算对神经网络产生的连续表示进行操作,仅在最终答案的预测中变得离散(啥?)
Layout
modules 的确定 取决于 the structure of the parse
所有的 leaves 都是 $\text{find}$ modules, 所有中间节点都是 $\text{transform}$ 或是 $\text{combine}$ modules, dependent on their arity,所有 root 节点 是 $\text{describe}$ 或是 $\text{measure}$ depending on the domain
 网络结构相同的,在同一个 batch 中处理
网络结构相同的,在同一个 batch 中处理
此转换过程的某些部分是特定于任务的,我们发现相对简单的表达式最适合自然图像问题 natural image questions,而合成数据(通过设计)则需要更深层次的结构
Generalizations
输入到 layout 的 input 可以是 natural language parser出来的 dependencies ,也可以是 SQL-like queries
4.3. Answering natural language questions
我们的最终模型将神经模块网络的输出 与 simple LSTM question encoder 的预测 prediction 相结合。(提供问题的完整信息)
- 因为 Parsing 后的简单表示 what is standing in the field 变成了 what(stand) 不会实质性地改变问题的语义的语法提示被丢弃。 The question encoder thus allows us to model underlying syntactic regularities 句法规则 in the data。
- allows us to capture semantic regularities 语义规律 it is reasonable to guess that what color is the bear? is answered by brown ,unreasonable to guess green
为了计算 answer,我们将LSTM的 final hidden state 通过一个 FC,将其 逐元素 添加到 NMN 的根模块生成的表示中,应用ReLU非线性,然后另一个 FC 层, 一个 softmax obtain a distribution over answers.
为了与以前的工作保持一致,我们将答案预测视为一个纯粹的分类问题:该模型从训练过程中观察到的答案中选择(无论它们是否包含多个单词),并将每个答案视为不同的类别。因此,在该最终预测层中的,例如 left side 和 left 之间没有共享参数。通过循环解码器一次生成一个单词得到的多单词答案的模型可以作为 extension
5. Training neural module networks
objective: find module parameters maximizing the likelihood of the data——softmax 结果
最后一层都是设计成 输出 在 label 上的概率分布, so each assembled network also represents a probability distribution. (视为分类问题)
由于用于回答问题的动态网络结构,某些权重比其他权重更频繁地更新。因此,我们发现具有单个权重自适应学习率 adaptive per-weight learning rates 的学习算法在性能上要比简单的梯度下降好得多。下面描述的所有实验均使用具有标准参数设置的 ADADELTA
6. Experiments: compositionality
这项工作的主要目标之一是学习用于深层语义组合的模型 deep semantic compositionality。 To eliminate mode-guessing as a viable strategy, all questions have a yes-or-no answer, but good performance requires that the system learn to recognize shapes and colors, and understand both spatial and logical relations among sets of objects.——为了消除模式猜测作为一种可行的策略,所有问题都回答是或否,但是良好的性能要求系统学会识别形状和颜色,并理解各组图形之间的空间关系和逻辑关系对象
为了产生一组初始的图像特征,我们将输入图像通过LeNet [22]的卷积部分,这个卷积部分与模型的 question-answering 部分共同训练。我们比较了我们的方法 与 以类似于[33]所述的方法 重新实现的 VIS + LSTM 基线,再次用LeNet替换了预先训练的图像嵌入。
此外,颜色检测器和注意力转换的行为符合预期(图2b),表明我们的联合训练模型正确地在模块之间分配了责任。这证实了我们的方法能够对复杂的组成现象进行建模,而先前的方法无法解决视觉问题。
7. Experiments: natural images
处理涉及自然图像的硬性感知问题 hard perceptual problems
we evaluate on the VQA dataset ,这是同类资源中最大的一种,由来自MSCOCO的200,000张图像组成[25],每张图像都由人类注释者生成的三个问题和每个问题十个答案配对。我们使用标准训练/测试集划分 ,仅训练那些 answer 标记 为高置信度的模型。
The visual input to the NMN is the conv5 layer of a 16-layer VGGNet [35] after max-pooling, with features normalized to have mean 0 and standard deviation 1. 出来 在 ImageNet 上预训练的 VGG,还比较了在 MSCOCO 上 fine-tuned 过的 VGG。
我们发现,即使始终在问题上涉及 量化 quantification,顶层模块 总是 describe,才能最好地完成此任务。
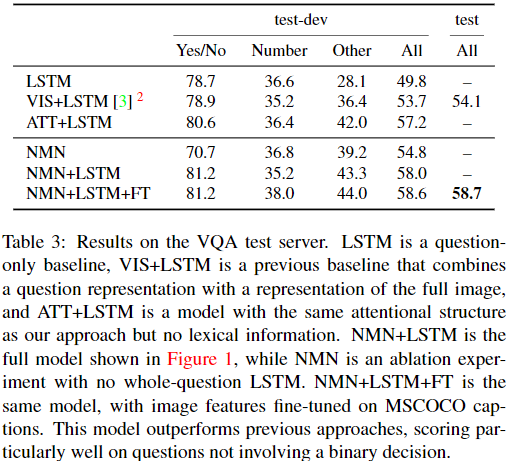
compare to :
- a text-only baseline (LSTM),
- a pre-vious baseline approach that predicts answers directly from an encoding of the image and the question [3]
- an at-tentional baseline (ATT+LSTM). This last baseline shares the basic computational structure of our model without syntactic compositionality: it uses the same network layout for every question (a find module followed by a describe module), with parameters tied across all problem instances
稀有 rare 单词(在训练数据中出现的次数少于10次)被映射到LSTM编码器和模块网络中的单个 tolen 或 模块实例。
对解析器输出的调查还表明,使用更好的解析器还有很大的空间可以改进系统性能。
通过手动检查发现: more complicated questions are more prone to picking up irrelevant predicates. 问题一复杂,可能找到不相关的谓词 。For example $\text{are these people most likely experiencing a workday?}$ is parsed as $\text{be(people, likely)}$ when the desired analysis is $\text{be(people, work)}$. Parser errors of this kind could be fixed with joint learning. 即 parse过程和后面的 module 选择等一起learn。
系统做出的谓词误判,包括可能的语义混淆(将纸板解释为皮革,将圆形窗框解释为时钟)(cardboard interpreted as leather, round windows interpreted as clocks)、 正常的词汇变化lexical variation(container for cup),以及使用优先级高但与图片无关的答案(describing a horse as located in a pen rather than a barn)。
8. Conclusions and future work
到目前为止,我们在预测网络结构 (dependency parse) 和学习网络参数之间保持了严格的区分。It is easy to imagine that these two problems might be solved jointly,但在整个训练和解码过程中,网络结构的不确定性仍然存在。这可以通过使用某些高级机制“参与”计算的相关部分,或者通过与现有的用于学习语义分析器learning semantic parsers的工具集成,来通过单片网络 monolithic network 来完成。我们在这项工作的后续工作中描述了联合学习模块行为和解析器的第一步[2]。
事实上,我们的神经模块网络可以训练以产生可预测的输出(即使自由组合),这一事实指向了更通用的“程序”范式。由神经网络构建而成。在这种范式中,网络设计人员(人工或自动化)可以访问神经零件的标准套件,从中构造用于执行复杂推理任务的模块。虽然视觉问题回答为该方法提供了自然的测试平台,但它的用途可能更广泛,可扩展到有关文档和结构化知识库的查询,或者扩展到更通用的函数逼近和信号处理。46