『』阅读笔记
- 基本变量和派生变量
- 基本变量的不确定性
- 模型的不确定性
- 参数的不确定性
专有名词
- Truncated normal distribution截断正态分布
- 贝叶斯学派认为参数是未观察到的随机变量,本身也有分布,因此,假定参数服从一个先验分布,然后基于观测到的数据来计算参数的后验分布。
- 可靠性分析
- linear limit-state function
- 点估计(point estimation)——用样本数据来估计总体参数, 估计结果使用一个点的数值表示“最佳估计值”,因此称为点估计。
- 高斯过程——参数方法需要推断参数的分布,而在非参数方法中,比如高斯过程,它可以直接推断函数的分布。reference 高斯过程Gaussian Process教程
Abstract
在工程模型领域对于风险和可靠度分析的不确定性的资源和特征将在这里讨论。有很多不确定性的资源可能存在着,它们可以总体被分为偶然的和认知的。不确定性被描述为认知的,是当建模者看到了可以通过更多的数据或者重新定义模型来降低不确定性的可能性。不确定性被分类为偶然的,是当建模者并不能提前看到降低这种不确定性的可能性。从务实的角度来看,对模型中的不确定性进行分类是有用的,因为这样就清楚了哪些不确定性具有减少的潜力。更重要的是,认知不确定性可能会导致事件之间的依赖,如果不正确地建模它们的特性,则可能无法正确地注意到这一点。讨论了在可靠性评估、成文设计、基于性能的工程和基于风险的决策中两种不确定性的影响。两个简单的例子说明了由认知不确定性引起的统计依赖对系统和时变可靠性问题的影响。
1 Introduction
不确定性的性质和处理方法长期以来一直是统计学家、工程师和其他专家讨论的话题 (see, e.g., Paté-Cornell 1996, Vrouwenvelder 2003, Faber 2005)。本文试图再次在结构可靠性和风险分析structural reliability and risk analysis 的背景下重新讨论这一问题。这份文件不大可能结束这一讨论。然而,我们希望它能在结构可靠性评估、成文法设计、基于性能的设计和基于风险的决策等structural reliability, codified design, performance-based design and risk-based decision-making. 问题上提供一些启示。特别是,我们将考虑系统可靠性和时变可靠性问题 systems reliability and time-variant reliability ,对于这些问题,适当处理 of uncertainties 比对时不变元件可靠性问题更为重要。我们认为,不确定性的性质和如何处理这些不确定性取决于上下文和应用。
工程问题,包括可靠性问题、风险问题和决策问题,无一例外地在模型范围内得到解决。这个范围包含一组物理和概率模型(或子模型),这些模型被用作对现实的数学理想化,为手头的问题提供一个解。模型范围可能包含内在固有的不确定量;此外,子模型总是不完美的,从而产生额外的不确定性。所以,在模型领域内一个重要的部分是对这些不确定性进行建模。对不确定性的性质和特性的任何讨论都应在模型领域的范围内说明。
虽然不确定性的来源可能很多,但在建模的背景下,可以方便地将不确定性的特征归类为 aleatory or epistemic 偶然事件不确定性(Aleatoric Uncertainty)和 认知不确定性(Epistemic Uncertainty)。aleatory这个词源自拉丁语,意思是掷骰子。因此,Aleatoric Uncertainty被认为是一种现象的内在随机性。 episteme一词来源于希腊语επιστη(认识论),意思是知识(knowledge)。因此,认知不确定性被认为是由于缺乏知识(或数据)造成的。在工程分析模型中方便地进行这种区分的原因是,通过引入辅助的非物理变量,可以在模型中表示缺乏知识-部分不确定性。这些变量从收集到的更多的数据或者使用更先进的科学准则中捕获信息。最重要的一点是,这些辅助变量以明确和透明的方式定义了统计依赖(相关性)。重点关注是在这些辅助变量上。
大多数工程问题都涉及这两种类型的不确定性。在建模阶段,有时,确定一个实际的不确定性是属于A或E是困难的。区分工作是模型建造者的工作。模型建造者做的决定取决于科学知识的总体情况,但是更多的是关于将模型的复杂程度限制在对从模型中产生的决策具有重大工程重要性的实际需要上。
符号约定:
一组输入变量 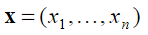 将值作为一组相应的基本随机变量
将值作为一组相应的基本随机变量 的结果的值。参数化概率子模型
的结果的值。参数化概率子模型 描述随机向量 $X$ 的分布,一组参数化的物理 子模型
描述随机向量 $X$ 的分布,一组参数化的物理 子模型 描述quantities $x$ 和 $m$ 的派生quantities
描述quantities $x$ 和 $m$ 的派生quantities  之间的关系,这些模型用于对研究中的可靠性或风险问题进行建模。随机变量 $X$ 之所以称为基本变量,是因为我们认为它们是直接可观察的,因此经验数据可用于它们。它们可能代表诸如材料特性(强度,延展性,韧性,疲劳寿命等),载荷特性(例如地震幅值,风速,波高),其他环境影响(例如温度,毒素浓度)之类的数量。-in,污染量)和几何尺寸(例如,横截面尺寸,支撑件位置,不平直度)。除非在针对模型开发的实验室或现场研究中,否则通常无法直接观察到 derived variables $y$ 。工程性能标准通常以这种推导的变量来描述,例如应力,变形,稳定性极限,破坏程度,损失,停机时间,下游水中毒素的浓度。
之间的关系,这些模型用于对研究中的可靠性或风险问题进行建模。随机变量 $X$ 之所以称为基本变量,是因为我们认为它们是直接可观察的,因此经验数据可用于它们。它们可能代表诸如材料特性(强度,延展性,韧性,疲劳寿命等),载荷特性(例如地震幅值,风速,波高),其他环境影响(例如温度,毒素浓度)之类的数量。-in,污染量)和几何尺寸(例如,横截面尺寸,支撑件位置,不平直度)。除非在针对模型开发的实验室或现场研究中,否则通常无法直接观察到 derived variables $y$ 。工程性能标准通常以这种推导的变量来描述,例如应力,变形,稳定性极限,破坏程度,损失,停机时间,下游水中毒素的浓度。
 总是不完美的现实数学理想化,并且包含不确定的错误。通常通过将这些子模型“拟合”到观测数据的过程来估计这些参数
总是不完美的现实数学理想化,并且包含不确定的错误。通常通过将这些子模型“拟合”到观测数据的过程来估计这些参数 
在可靠性和分线分析中的很多问题都设计上述元素。通过这篇文章我们会使用这些元素来讨论建模中的不确定性和在不同的应用上下文中评定风险和可靠性评估之间的相关性。
2 Sources of uncertainty
- 基本随机变量 X 固有的不确定性,例如可以直接测量的材料属性常数和载荷值固有的不确定性。
- 由于选择概率子模型的 form 而导致的不确定模型误差
- 由选择物理子模型引起的不确定建模误差,用于描述派生变量
- 概率和物理子模型的 参数 估计中的统计不确定性。
- 测量观测值涉及的不确定性误差,据此可以估算参数 。这些包括间接测量中涉及的错误,例如通过代理进行量测,例如材料强度的无损检测。
- 由对应于派生变量 $y$ 的随机变量 $Y$ 建模的不确定性,除上述所有不确定性外,还可能包括由计算误差,数值逼近或截断产生的不确定性误差。例如,通过有限元程序对非线性结构中的荷载效应进行计算时,会采用迭代计算,这总是会涉及收敛容限和截断误差
Interpolation errors、Model bias 、Numerical errors 、Observational error 、Parameter uncertainty
3 Categorization of uncertainties
3.1. Uncertainty in basic variables
考虑描述材料特性常数(例如混凝土的抗压强度)的基本随机变量X。直接测量的X中的不确定性应归类为偶然性Aleatoric还是认知性Epistemic?答案取决于具体情况。如果所需强度是现有建筑物中混凝土的强度,则如果确定可以对从建筑物中取出的样本进行测试,从而得出有关强度的信息,则不确定度应归类为认知性Epistemic。当然,测试可能会涉及随机的测量误差,尤其是在使用非破坏性方法的情况下。如果有可能考虑替代的测量方法,则该测量不确定度也应归类为认知的Epistemic。另一方面,例如,如果不尝试进行与混凝土生产控制有关的更详细的建模,则将来建筑物中混凝土强度的不确定性应归为偶然性Aleatoric。在建筑物建成之前,不会进行任何测试来减少未来建筑物混凝土强度所固有的可变性。
需求(负载)变量的情况有些不同,因为在评估现有建筑物和未来建筑物的可靠性时,人们通常会对需求值的未来实现感兴趣。因此,在这种情况下,基本需求变量的不确定性通常归为偶然性。
重申基本变量和派生变量之间的区别很重要。这是建模人员通常根据标准工程实践做出的选择。考虑例如年度最大风速,这在设计塔架时可能会引起关注。建模者可以选择考虑这一点作为基本变量,在这种情况下,他/她将采用概率子模型(可能从某些标准建议中选择)以经验方式 empirically获得年度最大风速数据。或者,如果没有此类数据,则分析人员可以选择对来自更基本的气象数据的风速使用预测子模型。在这种情况下,年风速是 形式为的导出变量,
形式为的导出变量, 其中x表示输入气象变量,表示风速的预测子模型 predictive sub-mode。下面将derived variable包含的uncertainties描述为模型不确定性的一部分,如我们所见,派生变量的不确定性可以归类为偶然不确定性和认知不确定性的组合。
其中x表示输入气象变量,表示风速的预测子模型 predictive sub-mode。下面将derived variable包含的uncertainties描述为模型不确定性的一部分,如我们所见,派生变量的不确定性可以归类为偶然不确定性和认知不确定性的组合。
在构建分析模型时,the arbitrariness in the choice of variables as basic or derived 使得问题中不确定性的分类取决于我们对子模型的选择。通过使用子模型,我们将经验数据依赖于其他基本变量,或者有时依赖于先验概率分配。地震危险性分析中有一个很好的例子。在这里,关注的是现场潜在地震地震动的强度,即 a demand variable。由于很难获得在特定地点经历的地面运动强度的经验数据,因此通常的做法是将强度量度与地震震级(可获得经验数据empirical data is available)和距离(与先验子模型相关priori sub-model can be used)相关联。可以使用-模型,例如,可以假定地震沿着活动断层的任何地方发生的可能性均等。这是通过“衰减attenuation”定律完成的,该定律可以看作是地面运动强度的预测子模型。在此公式中,地面运动强度成为一个derived variable,而基本变量是地震震级和距离。在选择此子模型时,我们将引入其他不确定性,这些不确定性可能同时具有偶然性和认知性成分,如以下部分所述。
值得注意的是,现有建筑物与未来建筑物中不确定性的不同分类规定了用于评估其可靠性的方法的根本差异。对于现有建筑物,可靠性评估应旨在评估以已知建筑物历史为条件conditioned on the known history of the building的可靠性。例如,有关建筑物在已知强度的地震中幸存下来的知识可用于截断强度分布的下尾部truncate the lower tail of the strength distribution。随着更多信息的收集,评估中的不确定性降低。本质上,这是信息更新的问题,贝叶斯技术非常适合于此。另一方面,例如在设计过程中,评估未来建筑物的可靠性的问题是确定从总体中抽取随机样本的状态之一determining the state of a random sample taken from a population。在考虑了所有合理的控制措施之后,在实现建筑物之前,无法使用直接信息进行更新。在评估现有结构与未来结构的可靠性时,这种区别在有关结构可靠性的文献中经常被忽略。
3.2 Model uncertainty
考虑物理量 $y$,其根据两组基本变量 x 和 z 唯一确定。我们希望开发一个数学模型(或子模型)来预测 y。y和(x,z)之间关系的确切形式通常是未知的。此外,建模者可能不知道y对z的依赖性,或者出于实用主义的考虑,他/她可能不希望include these variables in a predictive model of y。例如,实际上不可能在变量 z 上收集数据,因此将其包括在模型中将无济于事
作为一个具体示例,请考虑上述地面运动强度衰减模型ground motion intensity attenuation model。我们深知,除了地震的震级和距离外,一个地点的烈度还很重要,诸如断层破裂的传播速度,地震波传播路径的机械特征,场地周围的地质特征等变量。但是,从务实的角度来看,很难甚至不可能测量给定站点的这些变量。因此,我们将它们排除在衰减模型中。这些变量以及我们可能不知道的其他变量构成了地震动衰减模型中缺失的变量z,地震动衰减模型中仅根据地震震级和距离来表示,这些变量构成模型基本变量x的向量。
<img src=”https://raw.githubusercontent.com/JasonGuojz/JasonGuojz.github.io/master/images/Aleatory or epistemic Does it matter//image-20200803114118997.png” alt=”image-20200803114118997” style=”zoom:80%;/>
残差值 $\epsilon$ 建模成 random variable 两个原因:
- 模型中缺少的 missing variables z 的影响
- 模型的 potentially inaccurate form 的影响。例如,y 和 x之间的关系可以是非线性的,而模型使用的线性形式。
通常,人们会对无偏模型unbiased model感兴趣。在这种情况下, ,通过将 ε 的 mean 设置为zero 来确定,此外,通过对模型进行适当的转换,通常可以使 ε 具有 标准偏差为 $\sigma_\epsilon$ 的正态分布——测量模型的不准确性——分布独立于x
,通过将 ε 的 mean 设置为zero 来确定,此外,通过对模型进行适当的转换,通常可以使 ε 具有 标准偏差为 $\sigma_\epsilon$ 的正态分布——测量模型的不准确性——分布独立于x
这被称为模型的同方差形式 homoskedastic form of the mode(Box and Tiao 1992)。因此,为了完全定义模型,需要估计的模型参数集为  当涉及多个子模型时,除了所有子模型的参数和标准偏差 外,还需要确定不同子模型的误差项之间的相关系数 correlation coefficients
当涉及多个子模型时,除了所有子模型的参数和标准偏差 外,还需要确定不同子模型的误差项之间的相关系数 correlation coefficients
现在,我们在(1)中的形式模型中检查不确定性的性质。如上所述,ε 解释了缺失变量 z 的不确定影响以及模型的潜在不准确形式。如果对模型进行改善以包括一个或多个缺失变量和/或数学表达式(解析或算法),则可以减少这两种不确定性,从而可以更好地近似正确的形式。从这个意义上讲,ε中的不确定性至少被归类为认知的。但是,由于我们有限的科学知识状态,可能无法让我们进一步完善模型的形式,而我们无法测量缺失的变量则可能会排除扩展模型的可能性。在这种情况下,ε 中至少一部分不确定性被归类为偶然性。尤其是,如果这些变量(尽管未知)被表征为偶然随机变量,则由于缺失变量的影响而引起的ε不确定性部分可以合理地分类为偶然变量。
现在转到概率模型(或子模型)。通常通过对可用数据进行理论分布拟合来选择此模型。有评估拟合优度goodness of the fit的各种方法 。但是,当关注概率较小的事件时(如大多数结构可靠性和风险问题的情况一样),概率分布的尾巴the tail of the probability distribution 就变得很重要。不幸的是,标准的拟合优度测试不能保证尾部贴合fit in the tail的准确性。例如,Ditlevsen(1994)表明,同样拟合的分布可能会导致概率估计值明显不同。因此,在计算概率时,特别是对于罕见事件,从假定的分布模型中会产生不确定幅度的误差。可以将这种错误归类为认知类别epistemic category,因为收集更多数据将可以更好地拟合分布,因此可以减少模型的不确定性。但是,与上述物理模型的情况不同,难以评估由分配模型的选择引起的误差的大小。一个有逻辑的方法是为所有可行的分布模型distribution models计算感兴趣的概率,并评估计算出的概率值的variability 。Der Kiureghian(1989)建议的第二种方法是参数化分布的选择parameterize the choice of the distribution。然后,通过参数中的不确定性来表示分布模型中的不确定性。但是,这两种方法都需要大量分析。

只是在非常特殊的问题中,人们才能将事件的可能性视为事件在发生变化的一长串独立重复中的物理发生的相对频率。在结构安全领域structural safety中,几个非常重要的不确定性来源在相同情况下不会表现出这种重复性行为。可以肯定地说,将稳定的长期发生频率解释为物理意义上的绝对概率属于乌托邦。因此,概率概念的有用性必须建立在另一个理性的基础上。但是,作为一种思维构造(和一种仿真工具),数学概率的相对频率解释relative frequency interpretation对于其作为有关事件发生的可信度的有用性起着决定性作用。为了使概率置信度模型经受伪造的务实测试 To make a probabilistic degree-of-belief model subject to a pragmatic test of falsification (a concept by Matheron based on Popper),因此可以作为客观工具辩护,有必要将某种类型的相对频率行为与概率相关联that some type of relative frequency behavior be associated with the prob-abilistic mode。
提到的所选概率分布的编码应视为结构可靠性工程专业人士对计算出的概率敏感的模型元素的共识。否则,由于竞争原因,工程实践将对不合理的分配尾部选择开放。此外,以此方式获得了有用的公共知识库,尤其是在认识不确定性分布的选择方面。显然,对于基于样本数据的分发,随着更多数据和更好质量的数据的出现,知识库应受到修订。
为了克服任意分布选择arbitrary distribution choice的问题,通过对公认的实践进行校准过程来开发概率代码probabilistic codes ,从而至少将概率用作比较和调整的手段是合理的。如果对无形效用值也进行了校准calibration,那么甚至可以在模型中使用标准化分布standardized distributions i进行最优决策,以使平均可接受的实践成为最优实践。
近年来,人们对基于性能的工程开发给予了极大的关注,特别是在建筑物和其他结构的设计上,以抵抗地震的力量(Cornell and Krawinkler 2000)。该方法的核心是承诺计算与各种结构性能要求相关的风险,包括罕见事件(例如极端损坏和倒塌)的风险。在该领域迅速发展的文献中,很少关注诸如尾部敏感性问题或建模和估计中固有的不确定性表征之类的问题。尽管本文可能对解决这个问题没有帮助,但它引起了人们的关注,并希望为依赖于罕见事件概率值的方法的基本问题和问题提供一些启示
3.3.Parameter uncertainty


首选方法是贝叶斯分析,该方法允许以参数形式包含主观专家意见的先验知识。参数估计中的不确定性直接与可用信息的数量和质量有关。在数量上,我们指的是可用观察样本的大小。 By quality, we refer to the accuracy in the observations. 观测中出现的任何测量误差都会使信息内容变差,从而使数据质量变差。质量也指先验的信息内容。这种分析现在已成为常规,我们将不再讨论更多细节。
参数不确定性是严格认知的 strictly epistemic ,因为估计中的不确定性会降低,并且可能随着可用观测数据的数量和质量的增加而渐近消失。
3.4.Final remark
上面的讨论可能会引发哲学上的问题,即是否存在任何偶然的不确定性。显然,这个问题在模型世界之外没有任何意义。从语言学的角度来看,所有不确定性都与缺乏知识一样。但是,如上所述,在概率模型(尤其是数学统计模型)中,将不确定性的分类为偶然的Aleatoric Uncertainty和认知的Epistemic Uncertainty是很方便的。因此,在模型世界中,认知一词的含义比没有知识的含义更窄the word epistemic assumes a more narrow meaning than just lack of knowledge。
假设我们了解了所有缺失的变量和确切的模型形式,那么考虑不需要偶然类别aleatory category的模型可能只是时间问题。甚至可以通过精确的预测模型来解释基本变量basic variables。在这样的世界中,如果存在不确定性,那只会是认知的epistemic。但是,这个乌托邦式的世界与当今的工程实践相距太远。将不确定性分为偶然性和认知aleatory and epistemic 的优势在于,我们由此可以弄清楚哪些不确定性可以减少,哪些不确定性至少在短期内不那么容易减少。这种分类有助于我们分配资源和开发选择工程模型。此外,为了正确地表述风险或可靠性问题 risk or reliability problems,必须更好地理解不确定性的分类。例如,认知不确定性可能会在系统组件的估计性能之间引入依赖关系 introduce dependence among the estimated performances of the components of a system,,非遍历不确定性non-ergodic uncertainties可能会在时间或空间事件序列之间引入依赖关系。在实践中,由于对不确定性的不正确处理,这些依赖性通常被忽略。下节中的示例演示了这种影响的影响
4 Influence of uncertainties
在本节中,我们提供两个示例来说明不确定性对可靠性评估uncertainties on reliability assessment的影响。第一个例子说明了由系统不确定性在系统组件之间引入的统计依赖性statistical dependence 的影响。第二个例子说明了时变可靠性问题中非遍历不确定性的影响,无论是认知的还是偶然的both epistemic and aleatory
4.1.System reliability
考虑一个 k-out-of-N 的系统。如果N个分量中至少有k个存活,则该系统将存活,其中$1\le k\le N$。极值k=1和k =N分别定义了并联和串联系统的特殊情况。为简单起见,我们假设组件具有统计独立且相同分布的capacities ,capacities 由随机变量 $X_1$ 表示,并且统计独立且相同分布的需求demands 由随机变量 $X_2$ 表示。本质上,组件capacities 和 demands 分别是random realizations from the distributions of $X_1$ 和 $X_2$ 。因此,组件具有相同极限状态函数 定义为:
$g(x)\le0$ 为失败事件,我们进一步假设 $X_1$ 和 $X_2$ 是正态分布的随机变量,with unknown means $\mu_1 \mu_2$ and known standard deviations $\sigma_1 \sigma_2$ 
 假设为了估计 $\mu_1 \mu_2$ 的可用信息是 以
假设为了估计 $\mu_1 \mu_2$ 的可用信息是 以  采样均值的对 size 为 n 的 capacity and demand values的 sample observations。使用贝叶斯建模很方便,其中 $\mu_1 \mu_2$ 被认为是贝叶斯随机变量
采样均值的对 size 为 n 的 capacity and demand values的 sample observations。使用贝叶斯建模很方便,其中 $\mu_1 \mu_2$ 被认为是贝叶斯随机变量 的实现。假设
的实现。假设  和 diffuse priors 扩散先验,these imply posterior distributions of
和 diffuse priors 扩散先验,these imply posterior distributions of  ,关于
,关于  的后验分布是正态的,有均值和
的后验分布是正态的,有均值和
如前所述,分布参数 $\mu_1 \mu_2$ 的统计不确定性本质上是 epistemic 。由于组件的容量和需求component capacities and demands are identically distributed同分布的。因此,分布参数的估计中固有的统计不确定性在系统组件的估计状态之间引入了统计依赖性。为了研究这种影响,我们进行如下操作:
观察到,对于线性极限状态函数和正态随机变量,对于给定 值,典型组件的条件可靠性指标
值,典型组件的条件可靠性指标

reliability index对应结构失效概率——材料背景
显然,由于统计不确定性,可靠性指标的不确定性与观察样本的大小直接相关。
4.2.Time-variant reliability
5 Conclusions
What My Deep Model Doesn’t Know
Gaussian processes, A network with infinitely many weights with a distribution on each weight is a Gaussian process
The same network with finitely many weights, put a probability distribution over each weight is known as a Bayesian neural network
dropout : can give us principled uncertainty estimates从某种意义上讲,不确定性估计基本上近似于我们的高斯过程的估计,在使用dropout防止过拟合时,可以把这个有限模型视为高斯过程的近似,you can extract model uncertainty without changing a single thing. 在优化目标函数时,实际上也在减小 KL divergence between your model and the Gaussian process。
以 a single hidden layer 的模型 and the task of regression.为例
 用两个 binary vectors做输入层和一层隐层的dropout
用两个 binary vectors做输入层和一层隐层的dropout ,这个回归 task 的目标函数定义为
,这个回归 task 的目标函数定义为

Gaussian process has been applied in both the supervised and unsupervised domains, for both regression and classification tasks 都在用。Gaussian process offers nice properties such as uncertainty estimates over the function values, robustness to over-fitting, and principled ways for hyper-parameter tuning. 对给定的输入集和相应的输出集,要估计一个函数 $y=f(x)$ Following the Bayesian approach we would put some prior distribution over the space of functions $p(f)$,then look for the posterior distribution over the space of functions given our dataset 条件后验概率
 得到的分布作为 极大似然估计 We can then perform a prediction with a test point $x^$
得到的分布作为 极大似然估计 We can then perform a prediction with a test point $x^$  输出的 $y^$ 的期望称为predictive mean of the model, and its variance is called the predictive uncertainty. 通过使用高斯过程对函数空间上的分布进行建模,我们可以分析评估回归任务中的相应后验,并估计分类任务中的后验。实际上,这意味着对于回归,我们在所有函数值上放置一个联合高斯分布,高斯先验?
输出的 $y^$ 的期望称为predictive mean of the model, and its variance is called the predictive uncertainty. 通过使用高斯过程对函数空间上的分布进行建模,我们可以分析评估回归任务中的相应后验,并估计分类任务中的后验。实际上,这意味着对于回归,我们在所有函数值上放置一个联合高斯分布,高斯先验?
Fun With Uncertainty
从 dropout 中学习不确定性
一个用dropout训练的网络,输入$x^{*}$ 输出预测的期望为 $\Bbb{E}(y^{*})$ 以及网络对这个预测的 confidence为 方差 $Var(y^{*})$
我们的dropout网络只是一个高斯过程近似,因此在回归任务中它将具有一定的模型精度(与我们假设的观测噪声相反)。我们如何得到这个模型的精度?
推导的
在输出预测时也使用 dropout(一般在训练时使用而在预测时不用),输入 $x^*$ 来仿真网络的输出,重复 T 次,with different units dropped every time。这些是我们的近似预测性后验样本。我们可以从这些样本中得到我们的近似后验均值和预测方差(我们的不确定性)的经验估计量。我们只需遵循这两个简单的方程式