『On Calibration of Modern Neural Networks』阅读笔记
方向:
对于 dataset shift 和 out-of-distribution dataset 问题相关的论文,包括了 Temperature scaling [1],Deep Ensemble [2],Monte-Carlo Dropout [3] 等方法。而 [4] 在统一的数据集上对上述一系列方法,测试了他们在 data shift 和 out-of-distribution 问题上的 accuracy 和 calibration
[1] Guo, C., Pleiss, G., Sun, Y. and Weinberger, K.Q. On Calibration of Modern Neural Networks. In International Conference on Machine Learning, 2017
[2] Lakshminarayanan, Balaji, Alexander Pritzel, and Charles Blundell. “Simple and scalable predictive uncertainty estimation using deep ensembles.” Advances in neural information processing systems. 2017.
[3] Gal, Y. and Ghahramani, Z. Dropout as a Bayesian approximation: Representing model uncertainty in deep learning. In ICML, 2016
[4] Snoek, Jasper, et al. “Can you trust your model’s uncertainty? Evaluating predictive uncertainty under dataset shift.” Advances in Neural Information Processing Systems. 2019.
Abstract
置信度校准(代表真实正确的可能性 与 预测概率估计值间匹配 的问题)对于许多应用中的分类模型非常重要。 我们发现,与十年前不同的是,现代神经网络的校准效果很差。通过广泛的实验,我们发现深度,宽度,重量衰减和批次归一化是影响校准的重要因素。 我们评估具有图像和文档分类数据集的最新体系结构上各种后处理校准方法的性能。 我们的分析和实验不仅提供了对神经网络学习的见解,而且为实际设置提供了简单明了的方法:在大多数数据集上,温度标定是Platt Scaling的单参数变体,在标定中非常有效 预测
1. Introduction
在现实世界的决策系统中,分类网络不仅必须准确,而且还应指出何时可能不正确。具体地说,一个网络除了它的预测之外,还应该提供一个校准的置信度a calibrated confidence——the probability associated with the predicted class label should reflect its ground truth correctness likelihood。良好的置信度估计提供了一个有价值的额外信息来建立用户的可信度,特别是对于神经网络,其分类决策通常很难解释。此外,良好的概率估计可用于将神经网络纳入其他概率模型。例如,可以通过将网络输出与语音识别中的language model相结合 或 带有相机信息相结合以进行物体检测 来 提高检测性能
在2005年,Niculescu-Mizil&Caruana(2005)表明,神经网络通常会在二元分类任务中产生经过良好校准的概率。 尽管当今的神经网络无疑比十年前更加准确,但我们惊奇地发现现代神经网络已不再经过良好的校准。 这在图1中可视化,在CIFAR-100数据集上比较了5层LeNet(左)(LeCun等,1998)和110层ResNet(右)(He等,2016)。
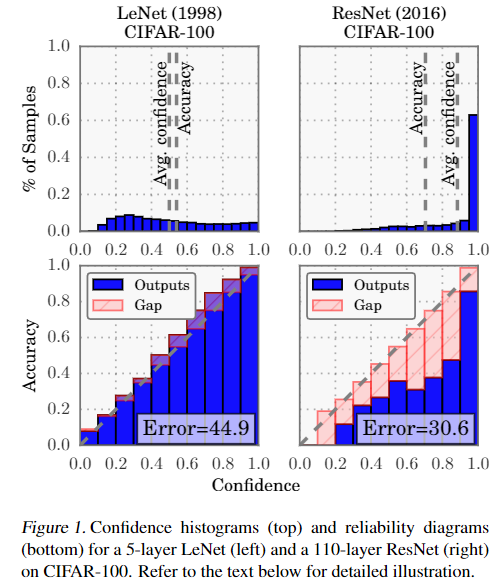
第一行以直方图的形式显示了the distribution of prediction confidence(即与predicted label相关的概率).LeNet的平均置信度与其准确度非常匹配,而ResNet的平均置信度实质上高于其准确性。 底部的 reliability diagrams(DeGroot和Fienberg,1983; Niculescu-Mizil和Caruana,2005)进一步说明了这一点,该图显示了准确度作为置信度的函数 accuracy as a function of confidence。 我们可以看到LeNet进行了很好的校准,因为置信度非常接近预期的准确性(即条形图沿对角线大致对齐)。 另一方面,ResNet的准确性更高,但并没有与其置信度相符。
在本文中,我们演示了几种计算机视觉和NLP任务,即神经网络所产生的置信度不能代表真实的概率。 此外,我们为可能会导致校准错误的网络训练和架构趋势提供了见识和直觉。 最后,我们在最先进的神经网络上比较了各种后处理校准方法,并介绍了我们自己的一些扩展。令人惊讶的是,我们发现了a single-parameter variant of Platt scaling (Platt et al., 1999) – 也就是我们说的 temperature scaling 通常是获得校准过的概率calibrated probabilities的最有效方法。 由于此方法很容易与现有的深度学习框架一起实施,因此可以在实际环境中轻松采用
2. Definitions
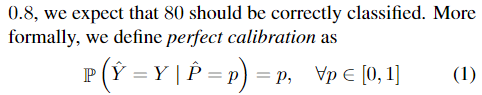
即要求 confidence $\hat{P}$ represents a true probability $p$
Reliability Diagrams
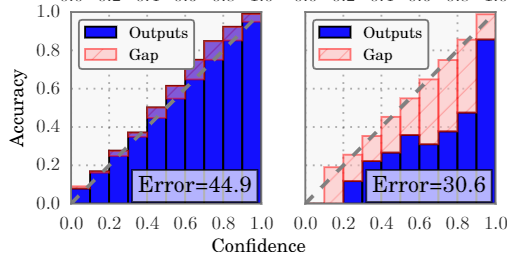
对角线 $ y=x$ 表示 perfectly calibrated
- Confidence
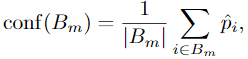
- Sccuracy
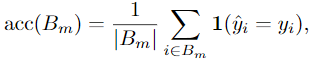
Expected Calibration Error (ECE)
a scalar summary statistic of calibration:
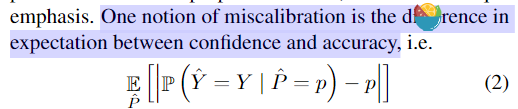
即 对每个 bin 做 weighted average 后的结果

Maximum Calibration Error (MCE)
估计最大偏差 deviation,is the largest calibration gap。对误差敏感的任务需要评估这个指标

Negative log likelihood
3. Observing Miscalibration
对改变 Model capacity、Batch Normalization、Weight decay、NLL 进行实验
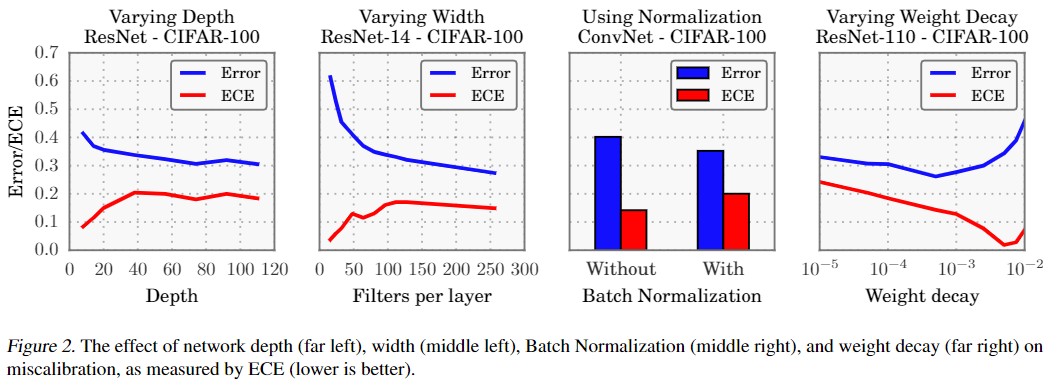
Model capacity
Recent work shows that very deep or wide models are able to generalize better than smaller ones, while exhibiting the capacity to easily fit the training set 越深的网络capacity越大则越容易过拟合。
现象:ECE度量随着模型的容量而显着增长。在训练期间,在模型能够正确(几乎)对所有训练样本进行分类之后,可以通过增加预测的置信度increasing the confidence of predictions来进一步最小化NLL(怎么增加的confidence)。模型容量的增加会降低训练的NLL,因此模型平均而言会更加(过度)自信
Batch Normalization
minimizing distribution shifts in activations within the neural network’s hidden layers
现象:使用批次归一化训练的模型往往tend to be more miscalibrated。 在图2的右中图中,我们看到,即使分类精度稍有提高,但应用批归一化时,六层ConvNet的 calibration 也较差。 我们发现,不管BatchNormalization模型上使用的超参数如何(即低或高学习率等),该结果都成立。
Weight decay
it is now common to train models with little weight decay, if any at all.
测试的时候,正则化的其他形式只有数据增强和 Batch Normalization。
现象:training with less weight decay has a negative impact on calibration
NLL can be used to indirectly measure model calibration.
现象:disconnect between NLL and accuracy。 Both error and NLL immediately drop at epoch 250, when the learning rate is dropped; however, NLL overfits during the remainder of training.
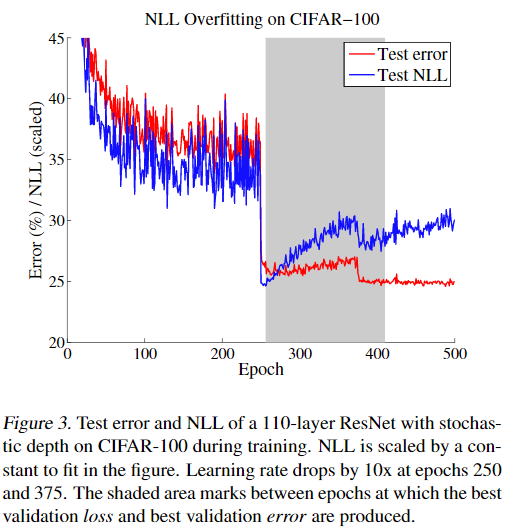
overfitting to NLL is beneficial to classification accuracy.
这一现象给出了 miscalibration错误校准 的具体解释: 网络以牺牲模型良好的概率为代价学习更好的分类精度。
我们可以将这一发现与最近研究大型神经网络泛化的工作联系起来。Zhang等人(2017)观察到,深度神经网络似乎违反了学习理论的普遍理解,即大的模型和少量的正则化将不能很好地泛化。观察到的 NLL 和 0/1损失(分类精度) 之间的断开表明,这些高容量模型不一定不会过拟合,而是,过拟合表现为概率误差probabilistic error 而不是分类误差classification error
4. Calibration Methods
4.1. Calibrating Binary Models
符号设置:
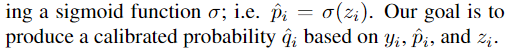
Histogram binning
对 $\hat{p_i}$ 划分区间 $B_m:a_m\le\hat{p_i}\le a_{m+1}$,落在区间内 则 calibrated probability $\hat{q_i} = \theta_m$
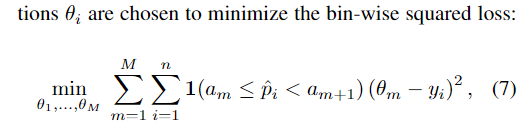
Isotonic regression保序回归
学习一个分段函数 $f$ 来将输出概率映射到校正概率 $\hat{q_i} = f(\hat{p_i})$

Bayesian Binning into Quantiles (BBQ)
Platt scaling
a parametric approach to calibration 参数化校正方法,前述均为非参数化
4.2. Extension to Multiclass Models
对于多分类任务
Extension of binning methods
解决方法是 treating the problem as K one-versus-all problems (Zadrozny & Elkan, 2002).
This extension can be applied to histogram binning, isotonic regression, and BBQ
Matrix and vector scaling
是 Platt scaling 的两种 multi-class 拓展
线性变化,优化目标 改变参数W和b, define vector scaling as a variant where W is restricted to be a diagonal matrix
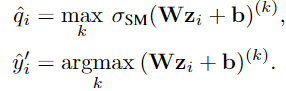
Temperature scaling
Platt scaling 的简单拓展,对比上面的方法
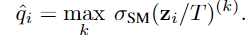
T is optimized with respect to NLL(Negative log likelihood) on the validation set.
In other words, temperature scaling does not affect the model’s accuracy. 改变的是模型输出的confidence。
常用在 knowledge distillation (Hinton et al., 2015) and statistical mechanics (Jaynes, 1957).
第一次在模型校正使用 calibrating probabilistic models,该模型等价于在对最后logits的约束下对输出概率分布的熵最大化 maximizing the entropy of the output probability distribution subject to certain constraints on the logits
5. Results
image classification and document classification neural networks
Calibration Results
实验结果发现 surprising effectiveness of temperature scaling
在视觉任务上优于其他所有方法,并在NLP数据集上与其他方法有竞争力
temperature scaling outperforms the vector and matrix Platt scaling variants, which are strictly more general methods
事实上,vector scaling基本上与temperature scaling的解决方案相同——学习过的向量有几乎恒定的分量,因此与每个分量除以 T 没有区别。换句话说,网络错误校准本质上是低维的network miscalibration is intrinsically low dimensional(怎么理解?)
Matrix scaling在有上百个类的数据集(例如鸟、汽车和CIFAR-100)上表现不佳,在1000个类的ImageNet数据集上也无法收敛。这是预期的,因为参数的数量与类的数量平方关系。任何具有数万(或更多)参数的校准模型,即使在应用正则化时,也会对一个小的验证集过度拟合
Binning methods 可以改善大多数数据集的校准,但不会超过temperature scaling。此外,分类方法往往会改变分类预测,这会损害准确性(请参见第S3节)。Histogram binning, the simplest binning method,尽管实际上这两种方法严格得多,但通常优于保序回归和BBQ。这进一步支持了我们的发现,即通过简单的模型可以最好地校正校准
Reliability diagrams.
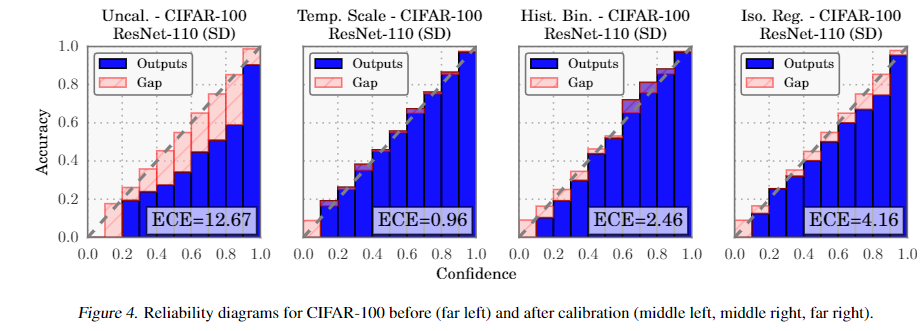
Using a conjugate gradient solver, the optimal temperature can be found in 10 iterations, or a fraction of a second on most modern hardware.
即使是optimal temperature的简单行搜索也比其他任何方法都要快。 vector and matrix scaling 的计算复杂度在 number of classes上(N )分别为线性和二次,反映了每种方法中参数对应 number of classes的数量。CIFAR-100 (K= 100)中 寻找一个接近最优的vector scaling solution 用共轭梯度下降至少需要多2个数量级的时间。Histogram binning and isotonic regression比temperature scaling多一个数量级, BBQ t比temperature scaling多约3个数量级